다음 프로젝트 사용 wsl에서 빌드
https://github.com/facebookresearch/sam2?tab=readme-ov-file

우선 해당 프로젝트는 메타에서 배포한 오픈소스 SAM 탐지 모델입니다.
파이썬 버전은 3.11.3을 사용합니다.
빌드환경은 wsl, anaconda3가 되겠습니다.
export PATH=/usr/local/cuda-12.4/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH
source ~/.bash_profile우선 위의 3줄을 실행하여 cuda toolkit버전을 12.4로 고정합니다.
위의 코드는 bash 쉘의 환경변수를 수정하여 기본적으로 12.4버전을 사용하도록 하는 것입니다.
git clone https://github.com/facebookresearch/sam2.git && cd sam2
pip install -e .
pip install -e ".[notebooks]"를 실행하시어 프로젝트를 빌드합니다. 그리고 사용할 모델을 다운 받아야 하는데, 이게 wsl에서 실행되어질 수 있도록 다운로드 스크립트를 수정할 필요가 있습니다. 따라서 다음을 따라합니다.
sudo apt update
sudo apt install dos2unix
cd chechpoints
dos2unix download_ckpts.sh
file download_ckpts.sh

다음과 같이 나오면 됩니다.
./download_ckpt.sh
cd ..
로 모델 다운로드를 완료합니다.
code .
를 통해 실행해봅시다.
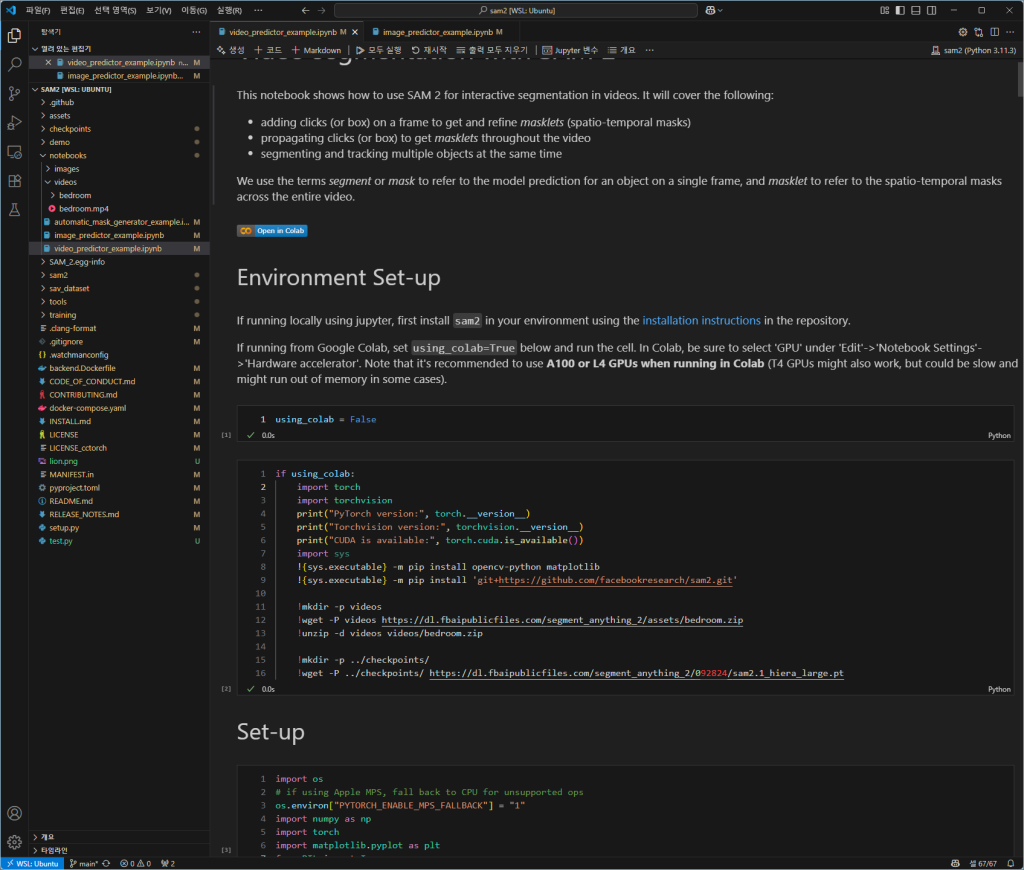

다음과 같이 vscode가 화면에 나올 것입니다.
notebooks 폴더에 들어갑니다.
video_predictor_example.ipynb 파일을 열고 실행해봅니다.
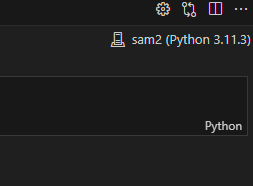
다만 다음과 같이 인터프리터가 wsl의 것으로 잘 잡혀 있어야 합니다.
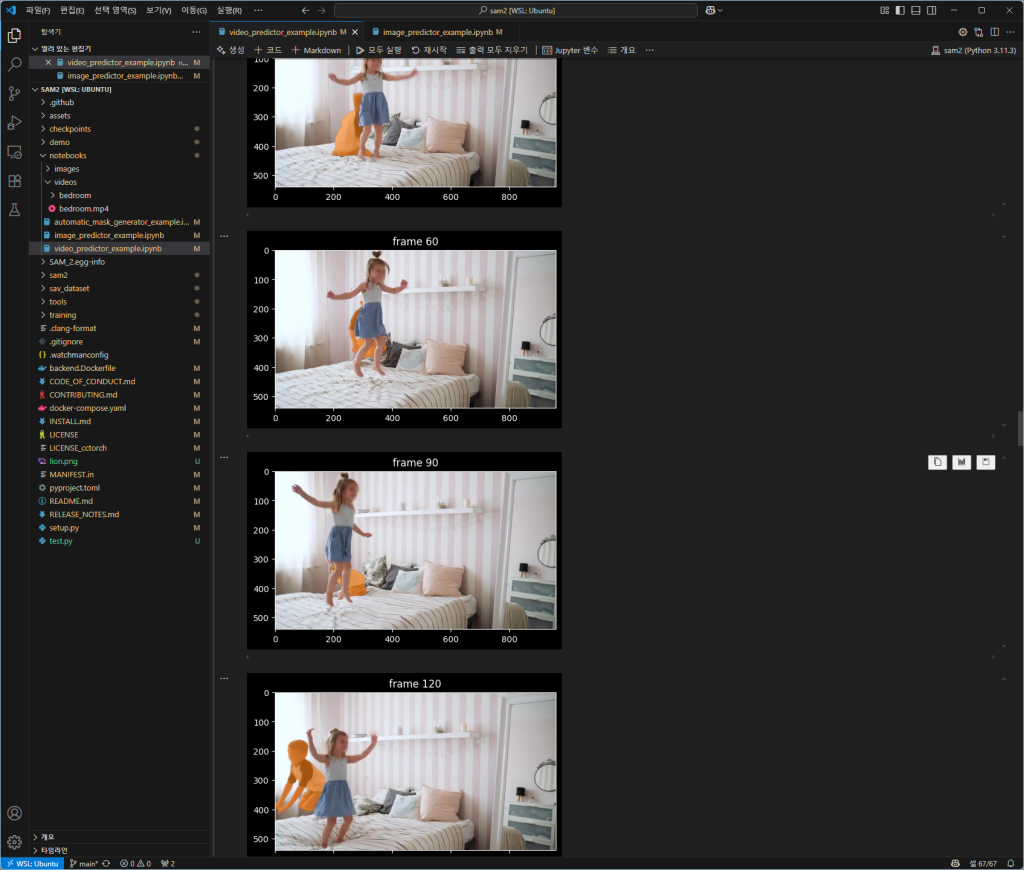
잘됩니다.
이제 윈도우에서 네이티브로 돌려봐야겠죠 이미 wsl에서 download 스크립트를 실행했으니 모델은 이미 있거든요
python -m venv .venv
.venv\Scripts\activate
pip install -e .
pip install -e ".[notebooks]"
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
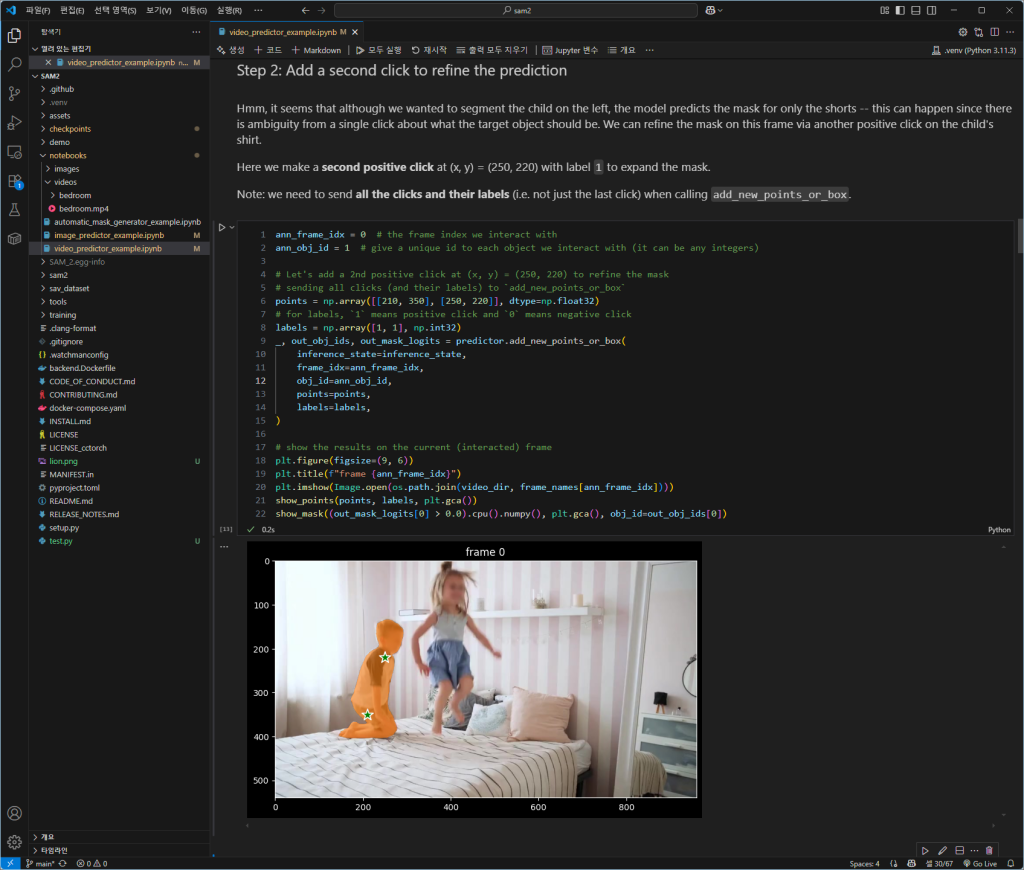
잘 되는군요
