total\Scripts\activate #가상환경 활성화
$cmakeArgs = @(
'-DGGML_CUDA=ON',
'-DLLAMA_CURL=ON',
'-DCMAKE_GENERATOR_TOOLSET="cuda=C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.4"',
'-DCMAKE_CUDA_ARCHITECTURES="86;89"',
'-DCMAKE_TOOLCHAIN_FILE=A:/vcpkg/scripts/buildsystems/vcpkg.cmake',
'-DCURL_INCLUDE_DIR=A:/vcpkg/packages/curl_x64-windows/include',
'-DCURL_LIBRARY=A:/vcpkg/packages/curl_x64-windows/lib/libcurl.lib'
)
$cmakeArgsString = $cmakeArgs -join ' '
$env:CMAKE_ARGS = $cmakeArgsString
pip install llama-cpp-python --no-cache-dir
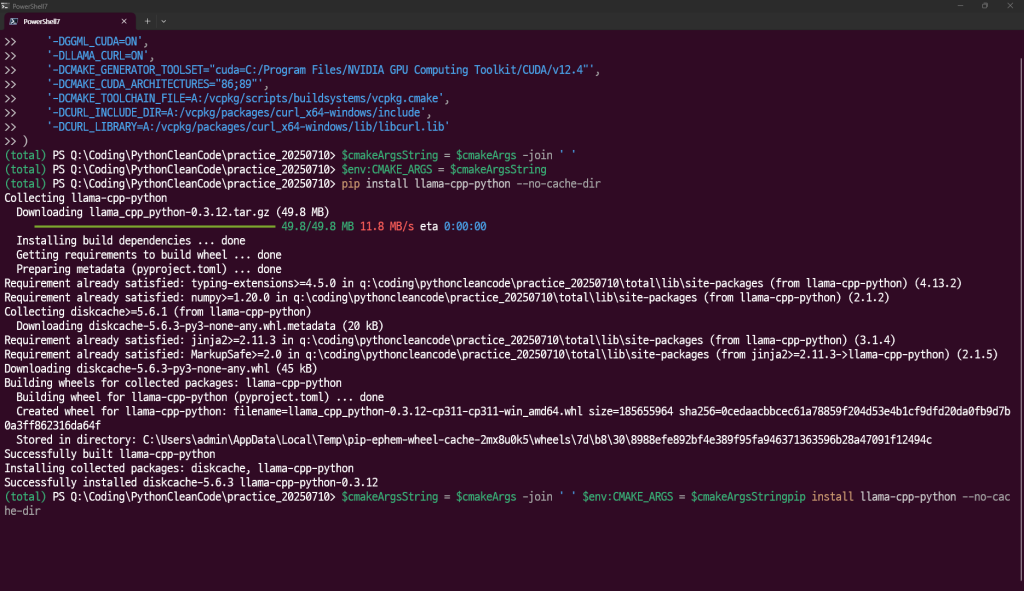
그럼 다음과 같이 설치가 진행되게 된다.
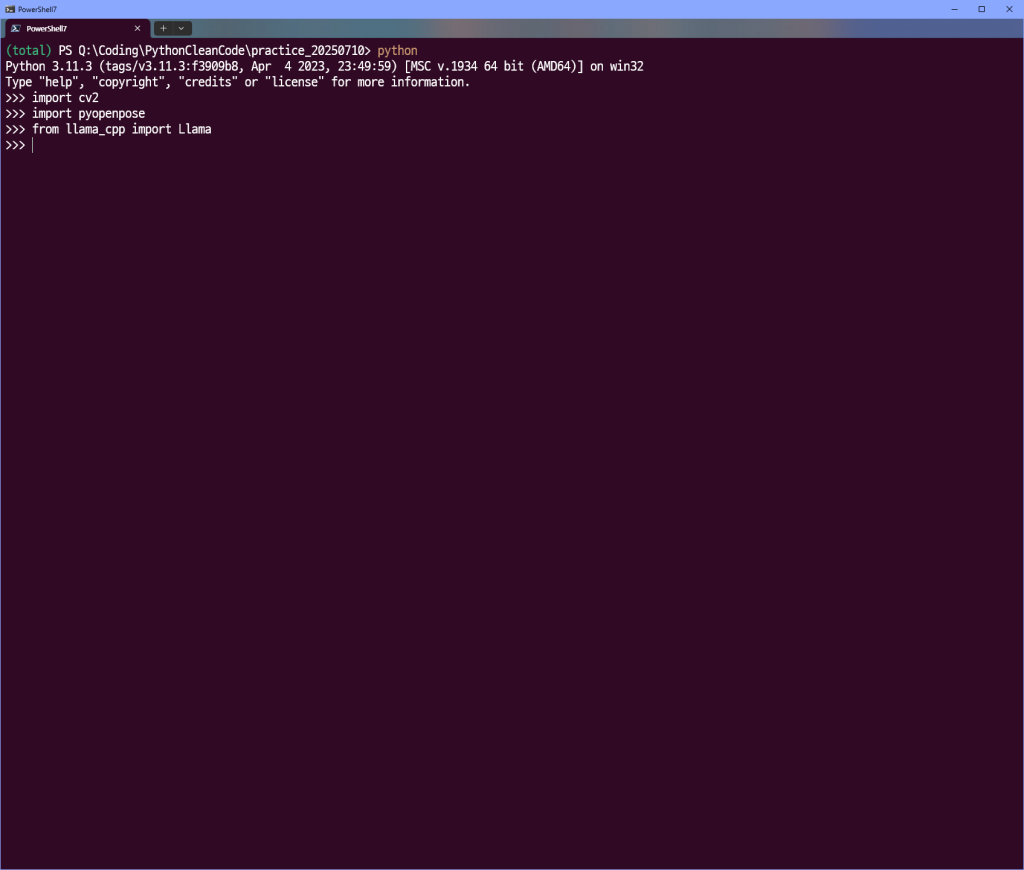
다른 패키지와도 충돌이 나지 않는 안정적인 모습~!
# llama-cpp-python 채팅 프로그램 예제
# 세계 최정상 프로그래머의 해법: 간단한 루프 기반 채팅, GPU 가속, 오류 처리 포함
import sys
from llama_cpp import Llama
# 모델 경로 설정 (사용자 환경에 맞게 수정)
MODEL_PATH = "llama-3-Korean-Bllossom-8B-Q4_K_M.gguf" # 다운로드한 파일 경로
# 모델 로드 (CUDA 지원: n_gpu_layers=-1로 모든 레이어 GPU 사용, 컨텍스트 크기 2048로 설정)
try:
llm = Llama(
model_path=MODEL_PATH,
n_gpu_layers=-1, # GPU 가속: -1=모든 레이어 GPU, 0=CPU만
n_ctx=2048, # 컨텍스트 길이: 대화 길이에 따라 증가 가능 (메모리 주의)
verbose=True # 로깅 활성화: 디버깅에 유용
)
print("모델 로드 완료! 채팅을 시작하세요. (종료: 'exit' 입력)")
except Exception as e:
print(f"모델 로드 실패: {e}")
sys.exit(1)
# 채팅 히스토리 (시스템 프롬프트로 한국어 특화 모델 초기화)
chat_history = [
{"role": "system", "content": "너는 도움이 되는 AI 어시스턴트야. 한국어로 자연스럽게 대답해."}
]
# 무한 루프 채팅 (프로 팁: 히스토리 유지로 컨텍스트 보존)
while True:
user_input = input("사용자: ")
if user_input.lower() == "exit":
print("채팅 종료!")
break
# 히스토리에 사용자 입력 추가
chat_history.append({"role": "user", "content": user_input})
# 모델 쿼리 (스트리밍 응답: 실시간 출력)
try:
response = llm.create_chat_completion(
messages=chat_history,
stream=True, # 스트리밍: 응답을 chunk로 받아 실시간 출력
max_tokens=512, # 최대 토큰: 응답 길이 제한 (메모리 절약)
temperature=0.7, # 창의성: 0.7=균형, 낮추면 더 사실적
top_p=0.9 # 다양성: 0.9=다양, 낮추면 더 집중
)
print("AI: ", end="", flush=True)
ai_response = ""
for chunk in response:
content = chunk['choices'][0]['delta'].get('content', "")
print(content, end="", flush=True)
ai_response += content
print() # 줄바꿈
# 히스토리에 AI 응답 추가 (다음 쿼리 컨텍스트 유지)
chat_history.append({"role": "assistant", "content": ai_response})
except Exception as e:
print(f"쿼리 오류: {e}")와 같은 코드를 실행하게 되면
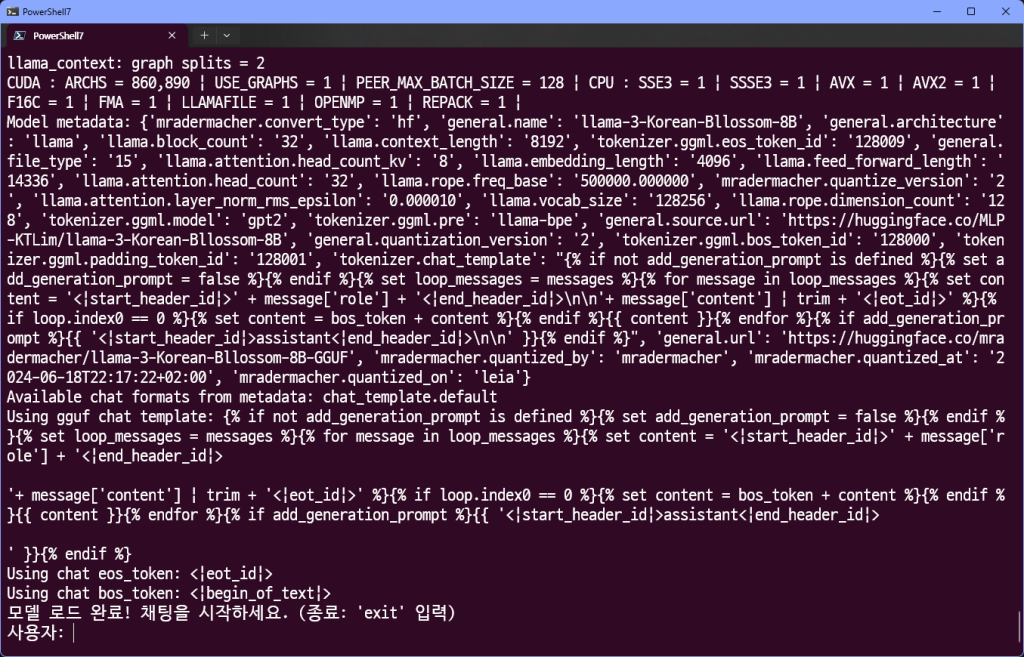
사용자: 노래 하나 작사해줘. 주제는 ‘콜라’에 대해서
AI: (제목: 콜라의 노래)
[verse 1]
어느 날, 손에 닿는 순간
콜라의 냄새가 나에게 다가온다
푸르름한 색과 깊은 맛
그 순간, 모든 스트레스가 사라져
[chorus]
콜라, 콜라, 나에게 오는 그 날
콜라, 콜라, 내 마음을 다스리는 그 맛
콜라, 콜라, 언제나 나의 곁에
콜라, 콜라, 내 일상을 밝게 비추는 그 빛
[verse 2]
하루종일의 피로, 그 모든 것이
콜라의 한 잔 속에 녹아들어
따스한 날씨의 여름, 혹은
추운 겨울의 밤에도 그 맛이 변함없이 그대로
[chorus]
콜라, 콜라, 나에게 오는 그 날
콜라, 콜라, 내 마음을 다스리는 그 맛
콜라, 콜라, 언제나 나의 곁에
콜라, 콜라, 내 일상을 밝게 비추는 그 빛
[bridge]
언제나 함께, 콜라와 나
그가 나에게, 그 나에게
콜라와 나, 그들은 우리
언제나 함께, 그들의 맛
[chorus]
콜라, 콜라, 나에게 오는 그 날
콜라, 콜라, 내 마음을 다스리는 그 맛
콜라, 콜라, 언제나 나의 곁에
콜라, 콜라, 내 일상을 밝게 비추는 그 빛
[outro]
콜라, 그 맛이 우리를
이제, 이제 그 날을
콜라, 그 맛이 우리를
이제, 이제 그 날을