이전 글에 이어지는 내용입니다.
이번에는 ExampleSelector를 정리해보려고 합니다.
아까의 FewShot예제를 사용한 코드는 좋습니다. 원하는 방식으로 잘되고요 그런데 비용(토큰) 소모가 심합니다.
저는 LangSmith를 사용하여 추적했기 때문에
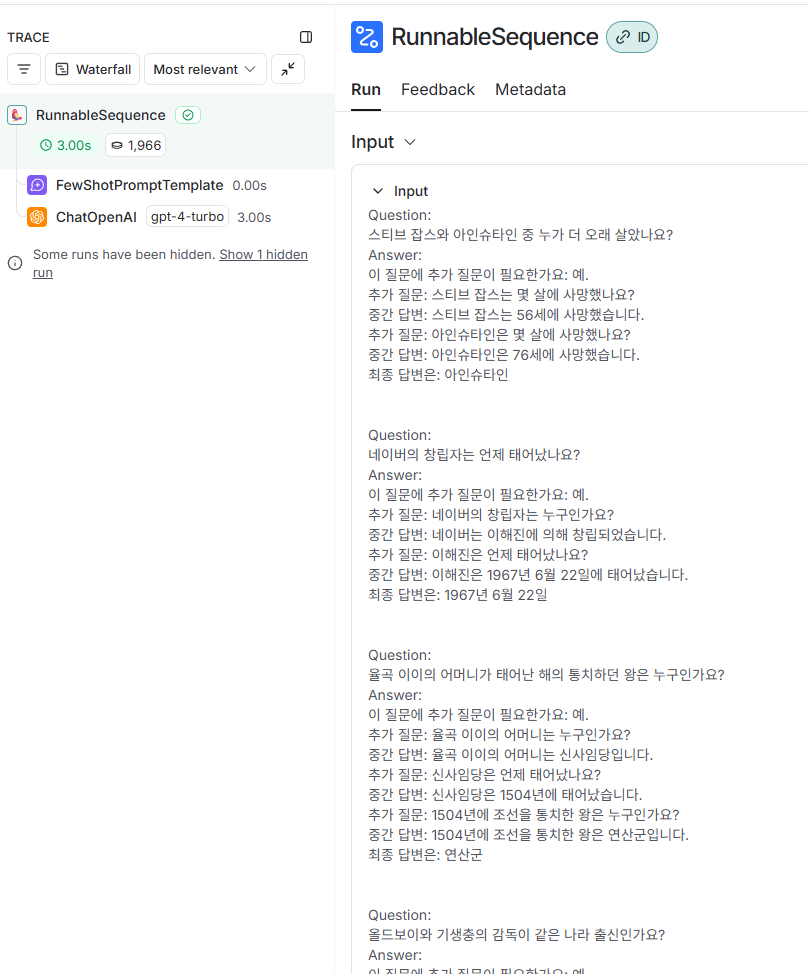
보시면 1,966 토큰이나 소모한 것을 보실 수 있습니다.
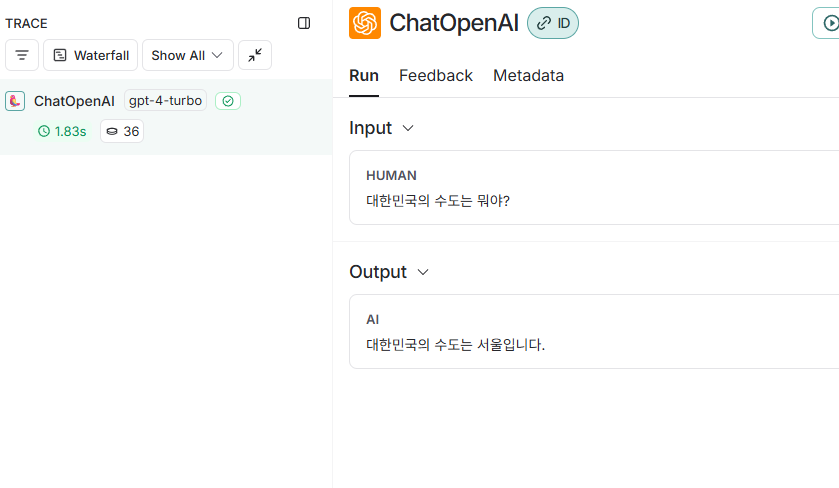
아래의 36토큰을 소모한 것과는 달리 너무나도 비교가 안될 만큼 낭비가 심하죠…
from langchain_core.example_selectors import (
MaxMarginalRelevanceExampleSelector,
SemanticSimilarityExampleSelector,
)
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# Vector DB 생성 (저장소 이름, 임베딩 클래스)
chroma = Chroma("example_selector", OpenAIEmbeddings())
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 여기에는 선택 가능한 예시 목록이 있습니다.
examples,
# 여기에는 의미적 유사성을 측정하는 데 사용되는 임베딩을 생성하는 임베딩 클래스가 있습니다.
OpenAIEmbeddings(),
# 여기에는 임베딩을 저장하고 유사성 검색을 수행하는 데 사용되는 VectorStore 클래스가 있습니다.
Chroma,
# 이것은 생성할 예시의 수입니다.
k=1,
)
question = "Google이 창립된 연도에 Bill Gates의 나이는 몇 살인가요?"
# 입력과 가장 유사한 예시를 선택합니다.
selected_examples = example_selector.select_examples({"question": question})
print(f"입력에 가장 유사한 예시:\n{question}\n")
for example in selected_examples:
print(f'question:\n{example["question"]}')
print(f'answer:\n{example["answer"]}')라는 코드가 있습니다.
“예제가 많은 경우 프롬프트에 포함할 예제를 선택해야 할 경우가 생기게 되는데,
강의에서 발췌
Example Selector는 이 작업을 담당하는 클래스“

API문서를 보시면
다음과 같이 사용가능한 selector들이 존재함을 보실 수 있습니다.
SematicsSimilarityExampleSelector -> ‘의미유사도 검색’ , 질문이 들어오면 질문과 유사도가 높은 것을 선택하여 주는 것 따라서 examples에서 가장 사용자의 질문과 유사한 예제를 뽑아 주겠다는 의미가 됩니다.
OpenAIEmbeddings() 는 추후에 다루도록 하겠습니다. 일단 지금은 문장 대 문장의 유사도 계산을 위한 임베딩을 위한 방법을 정의해놓은 것이라고 보시면 되겠습니다.
# Vector DB 생성 (저장소 이름, 임베딩 클래스)
chroma = Chroma("example_selector", OpenAIEmbeddings())위의 구문은 Chroma라는 벡터 스토어링 방식을 말하는 것입니다. 즉 문장들을 저장해놓고 유사도를 계산하는 것을 의미한다고 보시면 되겠습니다. 예제들을 저장하는 용도
# 입력과 가장 유사한 예시를 선택합니다.
selected_examples = example_selector.select_examples({"question": question})를 사용하면 아까 k = 1로 했기 때문에 가장 유사성이 높은 예제 하나를 가져와 줍니다.
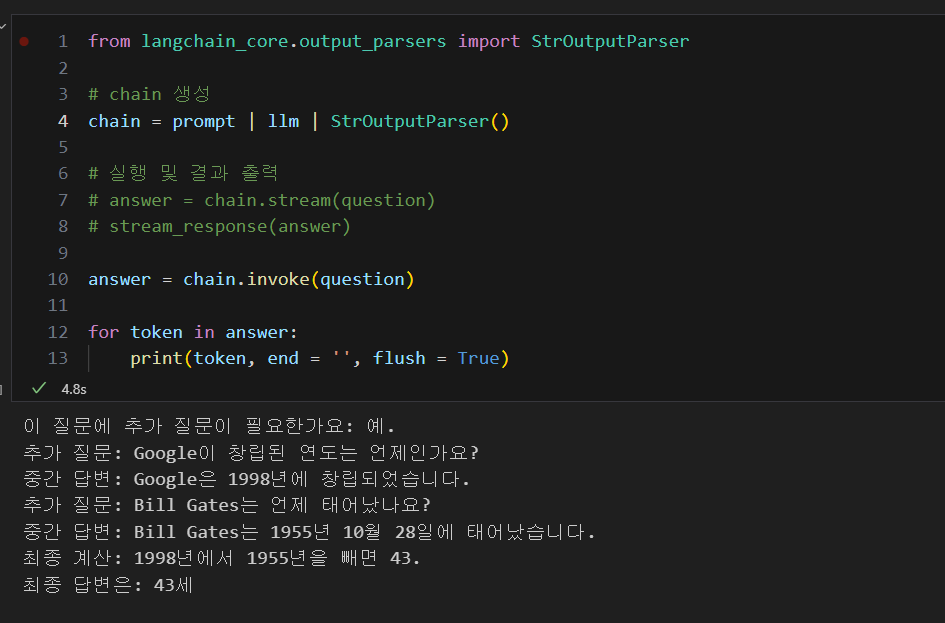
와 같이 나오게 됩니다.
같은 내용을 fewshot으로 검색시
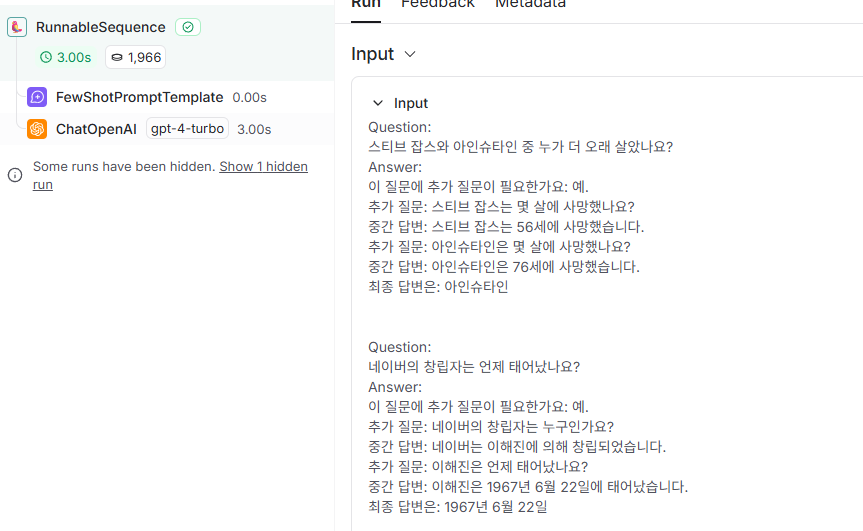
exampleselector로 검색시
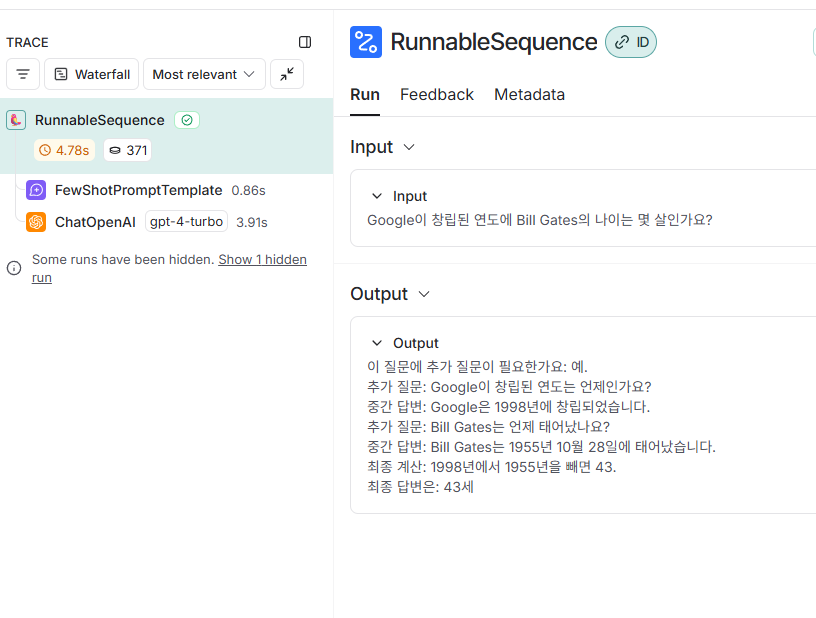
토큰을 절약할 수 있게 되었습니다.