import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import numpy as np
training_data = datasets.FashionMNIST(
root = "data",
train = True,
download = True,
transform = ToTensor(),
)
#Download test data from open datasets.
test_data = datasets.FashionMNIST(
root = "data",
train = False,
download= True,
transform= ToTensor(),
)
batch_size = 64;
# Creat data loader;
train_dataloader = DataLoader(training_data, batch_size = batch_size)
test_dataloader = DataLoader(test_data, batch_size = batch_size)
#X: 입력 이미지 데이터의 배치 텐서(batch tensor). 각 이미지는 의류 아이템의 28 * 28 그레이 스케일 픽셀 값으로 구성되어 있으며, 모델의 입력으로 사용됨
#y : 해당 이미지들의 라벨 (ground truth) 배치 텐서
for X, y in test_dataloader:
print(f"Shape of X [N , C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(f"using {device} device")
#Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28* 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X,y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
#to(device)는 메모리에 텐서롤 저장하는 것(vram)
#Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
#BackPropagation
loss.backward()
'''
Computation Graph구축(Forward Pass)
모델의 forward pass 중, requires_grad = True인 텐서(보통 모델 파라미터)에 대한 연산을 추적함.
각 연산은 graph의 노드(node)로 기록되며, 텐서의 grad_fn속성이 이를 가르킴.
pred = model(X)
에서 pred의 grad_fn은 모델의 마지막 연산을 참조
graph는 DAG(Direct Acyclic Graph) 형태로 , leaf nodes(입력 파라미터)부터 output(loss) 까지 연결됨
Backward Pass시작(Gradient Computation)
loss.backward() 호출 시, loss(스칼라 텐서)가 starting point가 됨.
autograd 엔진이 graph를 역순으로 traversal:각 노드에서 chain_rule을 적용해 입력에 대 그래디언트를 계산함.
지원 타입.float, complex텐서(half, float, double) 등.leaf tensors의 .grad 속성에 그래디언트가 누적됨.
Gradient Accumulation:
여러 backward 호출 시 .grad에 그래디언트가 더해집니다. 이는 미니배치 학습이나 gradient accumulation 테크닉에 유용합니다.
초기 .grad가 None이면 자동으로 생성 (param과 strides 맞춤). create_graph=True 시 higher-order derivatives(2차 미분) 지원, 하지만 메모리 비용 증가.
Hooks와 Non-Leaf Tensors:
Hooks: backward 중 사용자 정의 동작 삽입 (e.g., gradient clipping). tensor.register_hook(fn)으로 등록.
Non-leaf tensors(중간 결과): 기본적으로 grad 누적 안 함. 필요 시 retain_grad() 호출 (디버깅용, 메모리 증가 주의).
구동 예시 (간단 수학): a = torch.tensor(2.0, requires_grad=True), b = a ** 2, loss = b.sum(). backward() 시, a.grad = 4.0 (chain rule: d(loss)/da = 2*a).
'''
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
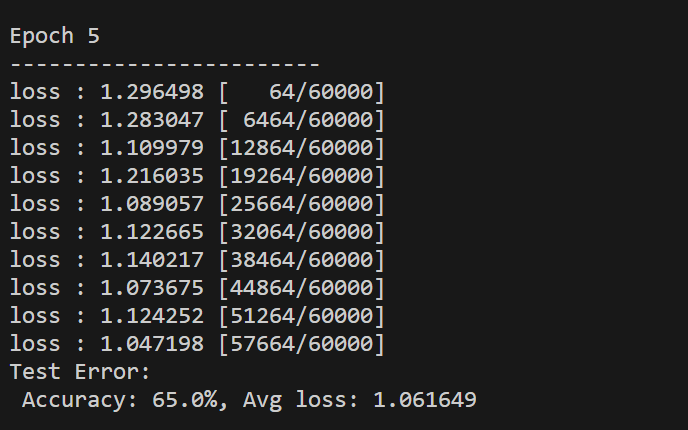
print(f"loss : {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100* correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")
다음의 코드를 실행했을 경우 다음과 같은 결과가 나오게 됨