
py.exe -3.11 -m venv .venv
.\.venv\Scripts\activate
python -m pip uninstall pip setuptools
python -m ensurepip --upgrade
pip3 install --upgrade pip
python.exe -m pip install --upgrade pip
pip install --upgrade setuptools
pip install timm>=1.0.17
pip install scipy
pip install pandas pydantic
pip install aiofiles==23.2.1
pip install huggingface_hub[hf_xet]
pip install langchain_teddynote
pip install langchain_openai
pip install opencv-python
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128
pip install timm>=1.0.17
pip install pytorch-lightning==2.5.2
pip install https://github.com/kingbri1/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu128torch2.7.0cxx11abiFALSE-cp311-cp311-win_amd64.whl
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.2.0-windows.post9/triton-3.2.0-cp311-cp311-win_amd64.whl
pip install https://github.com/woct0rdho/SageAttention/releases/download/v2.1.1-windows/sageattention-2.1.1+cu128torch2.7.0-cp311-cp311-win_amd64.whl
git clone https://github.com/ace-step/ACE-Step.git
cd ACE-Step
pip install -e .llama.cpp 설치
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
vcpkg install curl:x64-windows
vcpkg integrate install
#저는 A드라이브에 설치해서 경로가 다를 수 있습니다. 이 점 참고하세요.
cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=ON -DCMAKE_GENERATOR_TOOLSET="cuda=C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.8" -DCMAKE_CUDA_ARCHITECTURES="86;89" -DCMAKE_TOOLCHAIN_FILE=A:/vcpkg/scripts/buildsystems/vcpkg.cmake -DCURL_INCLUDE_DIR=A:/vcpkg/packages/curl_x64-windows/include -DCURL_LIBRARY=A:/vcpkg/packages/curl_x64-windows/lib/libcurl.lib
cmake --build build --config Release
- llama.cpp python biding설치 GPT-OSS GGUF 구동 위해
git clone https://github.com/abetlen/llama-cpp-python
cd llama-cpp-python
python -m ensurepip --upgrade
python -m pip install https://files.pythonhosted.org/packages/b7/3f/945ef7ab14dc4f9d7f40288d2df998d1837ee0888ec3659c813487572faa/pip-25.2-py3-none-any.whl
$cmakeArgs = @(
'-DGGML_CUDA=ON',
'-DLLAMA_CURL=ON',
'-DCMAKE_GENERATOR_TOOLSET="cuda=C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.8"',
'-DCMAKE_CUDA_ARCHITECTURES="86;89"',
'-DCMAKE_TOOLCHAIN_FILE=A:/vcpkg/scripts/buildsystems/vcpkg.cmake',
'-DCURL_INCLUDE_DIR=A:/vcpkg/packages/curl_x64-windows/include',
'-DCURL_LIBRARY=A:/vcpkg/packages/curl_x64-windows/lib/libcurl.lib'
)
$cmakeArgsString = $cmakeArgs -join ' '
$env:CMAKE_ARGS = $cmakeArgsString
pip install llama-cpp-python --no-cache-dirTRELLIS 설치
git clone --recurse-submodules https://github.com/microsoft/TRELLIS.git
cd TRELLIS
git submodule init
git submodule update --remote
git pull origin main
pip install pillow imageio imageio-ffmpeg tqdm easydict opencv-python-headless scipy ninja rembg onnxruntime trimesh xatlas pyvista pymeshfix igraph transformers
pip install git+https://github.com/EasternJournalist/utils3d.git@9a4eb15e4021b67b12c460c7057d642626897ec8
pip install kaolin -f https://nvidia-kaolin.s3.us-east-2.amazonaws.com/torch-2.7.0_cu128.html
git clone https://github.com/NVlabs/nvdiffrast.git ./tmp/extensions/nvdiffrast
pip install ./tmp/extensions/nvdiffrast
cd ./tmp
git clone https://github.com/autonomousvision/mip-splatting.git
cd mip-splatting
pip install -r requirements.txt
pip install --upgrade setuptools wheel
pip install submodules/diff-gaussian-rasterization
#현재 경로가 CapstonProject/TRELLIS 경로인지 확인
git clone https://github.com/smthemex/ComfyUI_TRELLIS.git
cd ComfyUI_TRELLIS/extensions/vox2seq
pip install .
#torch 버전이 overwrite되므로 다시 torch를 설치한다.
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 xformers==0.0.30 --index-url https://download.pytorch.org/whl/cu128
pip3 install spconv-cu124 #minor 호환모드로 동작
python -c "import spconv; print(spconv.__version__); import torch; print(torch.cuda.is_available())"
set SPCONV_DISABLE_JIT="1"
pip install gradio_litmodel3d
pip install numpy==1.26.4
pip install numba==0.61.2
pip install gradio==5.33.2
set ATTN_BACKEND=flash-attn
set SPCONV_ALGO=native
cd ../TRELLIS
python ./app.py실행 테스트
import sys
import os
from pathlib import Path
import torch
current_path = Path(__file__).resolve()
# 부모 디렉터리를 얻어 sys.path에 추가
sys.path.append(str(current_path.parent))
parent_dir = os.path.dirname(current_path)
# 'ACE-Step' 디렉터리의 절대 경로를 구성
ace_step_path = os.path.join(parent_dir, 'ACE_STEP')
sys.path.append(ace_step_path)
# 경로 추가 확인
print(sys.path)
print(os.path.dirname(os.path.abspath(__file__)))
from TRELLIS.create import create_3d_from_image
from ACE_STEP import infer_function as ace
print("import ok")
if __name__ == "__main__":
audio = ace.run_ace_step_inference()
file3d = create_3d_from_image(file_path="data/doggum.jpg", output_file= "cutecat.mp4")


import sys
import os
from pathlib import Path
import torch
current_path = Path(__file__).resolve()
# 부모 디렉터리를 얻어 sys.path에 추가
sys.path.append(str(current_path.parent))
parent_dir = os.path.dirname(current_path)
# 'ACE-Step' 디렉터리의 절대 경로를 구성
ace_step_path = os.path.join(parent_dir, 'ACE_STEP')
sys.path.append(ace_step_path)
# 경로 추가 확인
print(sys.path)
print(os.path.dirname(os.path.abspath(__file__)))
from TRELLIS.create import create_3d_from_image
from ACE_STEP import infer_function as ace
print("import ok")
def stable_diffusion_test():
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# 모델 로드 (이전과 동일)
pipe = StableDiffusionPipeline.from_single_file(r"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors", torch_dtype=torch.float16)
# LoRA 로드 (이전 checkpoint-500 디렉토리 지정 – 파일 대신 폴더로 변경, 에러 해결)
pipe.load_lora_weights(r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto\checkpoint-500", lora_scale=0.8) # 디렉토리 경로만! 안쪽 safetensors 자동 로드
if torch.cuda.is_available():
pipe = pipe.to('cuda')
else:
print("cuda 없음: cpu로 실행")
# 메모리 최적화 (이전처럼)
pipe.enable_attention_slicing()
# 프롬프트 (이전 그대로)
prompt = "Naruto in Nine-Tails mode with red eyes, fox-like aura, orange cloak, standing on mars crater with alien stars, fierce expression, chakra energy beams, best quality, masterpiece, detailed fur texture, epic composition, 4K resolution, dramatic shadows"
negative_prompt = "pixelated, overexposed, underexposed, noise, artifacts, fused fingers, three legs, bad proportions, extra eyes, realistic, photo, ugly face, low quality, missing details"
# 이미지 생성 (이전 그대로)
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
# 저장 (이전 그대로)
output_dir = "generated_images_naruto_tweak"
os.makedirs(output_dir, exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, f"image_{i}.png"))
print(f"{len(imgs)}개 이미지 생성 완료: {output_dir} 폴더 확인 – LoRA scale 0.8로 Naruto 특징 강조 테스트!")
# 프로 루프: checkpoint 디렉토리 지정 (파일 대신 폴더로 변경, 에러 해결 + skip 로직 추가로 끈질기게 안정)
checkpoints = [500, 1000, 1500] # 이전 루프
scales = [0.6, 0.8, 1.0] # 이전
base_path = r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto"
for ckpt in checkpoints:
ckpt_dir = os.path.join(base_path, f"checkpoint-{ckpt}")
if not os.path.exists(ckpt_dir): # 존재 안 하면 skip – 끈질기게 에러 방지
print(f"Checkpoint {ckpt} 디렉토리 없음 – 훈련 계속 돌려주세요!")
continue
for scale in scales:
pipe.load_lora_weights(ckpt_dir, lora_scale=scale) # 디렉토리 경로만! 자동 safetensors 로드
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
sub_dir = f"ckpt{ckpt}_scale{scale}"
os.makedirs(os.path.join(output_dir, sub_dir), exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, sub_dir, f"image_{i}.png"))
print("checkpoint & scale 비교 완료 – Naruto 특징 강해지는 버전 골라보세요!")
if __name__ == "__main__":
#audio = ace.run_ace_step_inference()
#file3d = create_3d_from_image(file_path="data/doggum.jpg", output_file= "cutecat.mp4")
stable_diffusion_test()
stable diffusion pipeline 정상 호출 확인 완료
MiniCPM 통합
pip install audioread==3.0.1
pip install certifi==2025.4.26
pip install cffi==1.17.1
pip install charset-normalizer==3.4.2
pip install comm==0.2.2
pip install debugpy==1.8.14
pip install decord==0.6.0
pip install einx==0.3.0
pip install encodec==0.1.1
pip install exceptiongroup==1.3.0
pip install executing==2.2.0
pip install filelock==3.13.1
pip install fsspec==2024.6.
pip install ipykernel==6.29.5
pip install pickleshare
import sys
import os
from pathlib import Path
import torch
current_path = Path(__file__).resolve()
# 부모 디렉터리를 얻어 sys.path에 추가
sys.path.append(str(current_path.parent))
parent_dir = os.path.dirname(current_path)
# 'ACE-Step' 디렉터리의 절대 경로를 구성
ace_step_path = os.path.join(parent_dir, 'ACE_STEP')
sys.path.append(ace_step_path)
# 경로 추가 확인
print(sys.path)
print(os.path.dirname(os.path.abspath(__file__)))
from TRELLIS.create import create_3d_from_image
from ACE_STEP import infer_function as ace
print("import ok")
def stable_diffusion_test():
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# 모델 로드 (이전과 동일)
pipe = StableDiffusionPipeline.from_single_file(r"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors", torch_dtype=torch.float16)
# LoRA 로드 (이전 checkpoint-500 디렉토리 지정 – 파일 대신 폴더로 변경, 에러 해결)
pipe.load_lora_weights(r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto\checkpoint-500", lora_scale=0.8) # 디렉토리 경로만! 안쪽 safetensors 자동 로드
if torch.cuda.is_available():
pipe = pipe.to('cuda')
else:
print("cuda 없음: cpu로 실행")
# 메모리 최적화 (이전처럼)
pipe.enable_attention_slicing()
# 프롬프트 (이전 그대로)
prompt = "Naruto in Nine-Tails mode with red eyes, fox-like aura, orange cloak, standing on mars crater with alien stars, fierce expression, chakra energy beams, best quality, masterpiece, detailed fur texture, epic composition, 4K resolution, dramatic shadows"
negative_prompt = "pixelated, overexposed, underexposed, noise, artifacts, fused fingers, three legs, bad proportions, extra eyes, realistic, photo, ugly face, low quality, missing details"
# 이미지 생성 (이전 그대로)
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
# 저장 (이전 그대로)
output_dir = "generated_images_naruto_tweak"
os.makedirs(output_dir, exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, f"image_{i}.png"))
print(f"{len(imgs)}개 이미지 생성 완료: {output_dir} 폴더 확인 – LoRA scale 0.8로 Naruto 특징 강조 테스트!")
# 프로 루프: checkpoint 디렉토리 지정 (파일 대신 폴더로 변경, 에러 해결 + skip 로직 추가로 끈질기게 안정)
checkpoints = [500, 1000, 1500] # 이전 루프
scales = [0.6, 0.8, 1.0] # 이전
base_path = r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto"
for ckpt in checkpoints:
ckpt_dir = os.path.join(base_path, f"checkpoint-{ckpt}")
if not os.path.exists(ckpt_dir): # 존재 안 하면 skip – 끈질기게 에러 방지
print(f"Checkpoint {ckpt} 디렉토리 없음 – 훈련 계속 돌려주세요!")
continue
for scale in scales:
pipe.load_lora_weights(ckpt_dir, lora_scale=scale) # 디렉토리 경로만! 자동 safetensors 로드
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
sub_dir = f"ckpt{ckpt}_scale{scale}"
os.makedirs(os.path.join(output_dir, sub_dir), exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, sub_dir, f"image_{i}.png"))
print("checkpoint & scale 비교 완료 – Naruto 특징 강해지는 버전 골라보세요!")
def test_minicpm():
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
# model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
# attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='flash_attention_2', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path="output.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)
if __name__ == "__main__":
test_minicpm()
audio = ace.run_ace_step_inference()
file3d = create_3d_from_image(file_path="data/doggum.jpg", output_file= "cutecat.mp4")
stable_diffusion_test()
위의 코드로 테스트 한다.
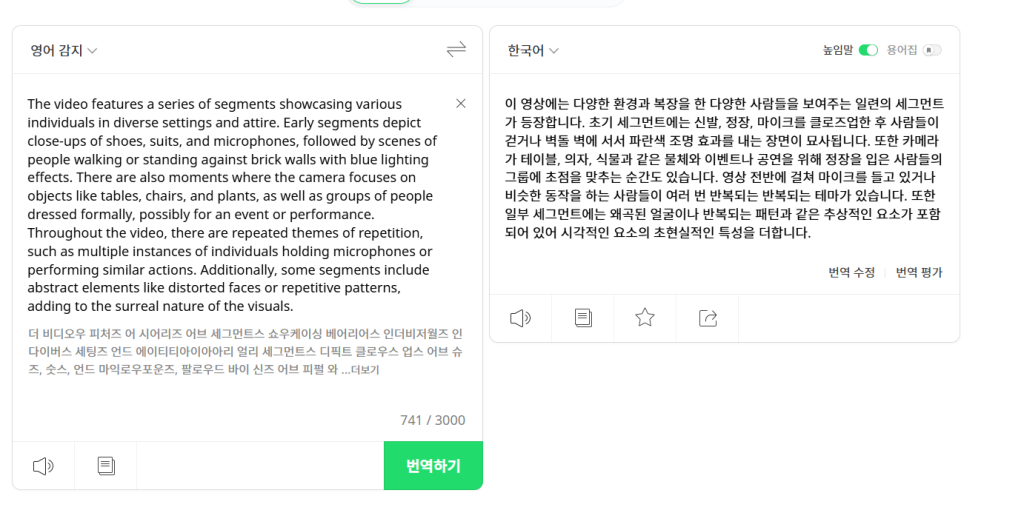
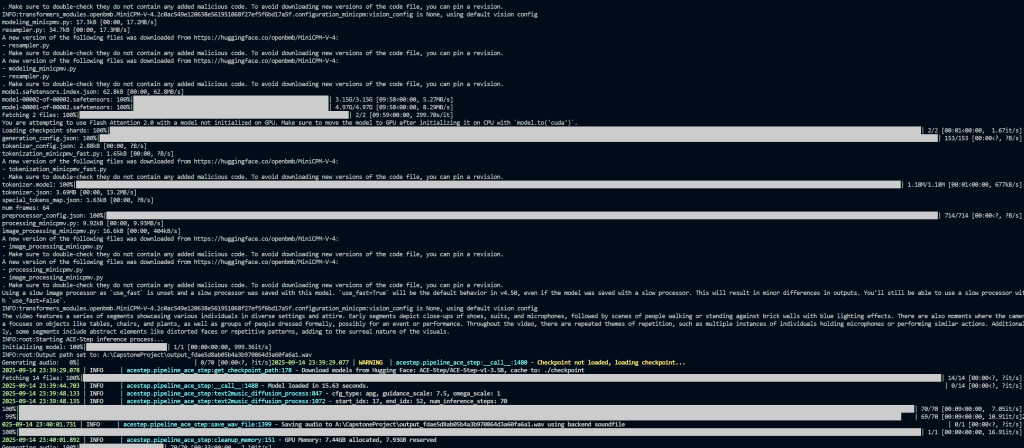
잘된다.
WGP 통합
pip install mmgp==3.5.7
pip install pynvml
pip install pyannote.audio
pip install ffmpeg-python
pip install misaki
pip install pyloudnorm
pip install open_clip_torch>=2.29.0
pip install tensordict>=0.6.1
pip install sounddevice>=0.4.0
pip install av
pip install hydra-core
pip install segment-anything
pip install rembg[gpu]==2.0.65
pip install numpy==1.26.4
pip install pip install mutagen
pip install moviepy==1.0.3
잘 된다.

xformers 쪽도 컴파일이 잘된다. 이는 triton이 올바르게 잡혔음을 의미한다.
설정을 건드린 뒤의 출력이다.
MMAudio는 WGP의 설치에 성공하면 자동으로 종속성이 갖춰진다.
python gradio_demo.py원본은 다음과 같이 무성이다.
다음과 같이 효과음과 배경음악을 생성해준다.
python demo.py --duration=8 --video="../output.mp4" --prompt "a dancing guys" 위 영상처럼 된다.
import gc
import logging
from argparse import ArgumentParser
from datetime import datetime
from fractions import Fraction
from pathlib import Path
import torch
import torchaudio
from mmaudio.eval_utils import (ModelConfig, VideoInfo, all_model_cfg, generate, load_image,
load_video, make_video, setup_eval_logging)
from mmaudio.model.flow_matching import FlowMatching
from mmaudio.model.networks import MMAudio, get_my_mmaudio
from mmaudio.model.sequence_config import SequenceConfig
from mmaudio.model.utils.features_utils import FeaturesUtils
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
log = logging.getLogger()
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
elif torch.backends.mps.is_available():
device = 'mps'
else:
log.warning('CUDA/MPS are not available, running on CPU')
dtype = torch.bfloat16
model: ModelConfig = all_model_cfg['large_44k_v2']
model.download_if_needed()
output_dir = Path('./output/')
setup_eval_logging()
def get_model() -> tuple[MMAudio, FeaturesUtils, SequenceConfig]:
seq_cfg = model.seq_cfg
net: MMAudio = get_my_mmaudio(model.model_name).to(device, dtype).eval()
net.load_weights(torch.load(model.model_path, map_location=device, weights_only=True))
log.info(f'Loaded weights from {model.model_path}')
feature_utils = FeaturesUtils(tod_vae_ckpt=model.vae_path,
synchformer_ckpt=model.synchformer_ckpt,
enable_conditions=True,
mode=model.mode,
bigvgan_vocoder_ckpt=model.bigvgan_16k_path,
need_vae_encoder=False)
feature_utils = feature_utils.to(device, dtype).eval()
return net, feature_utils, seq_cfg
net, feature_utils, seq_cfg = get_model()
@torch.inference_mode()
def video_to_audio(video: str, prompt: str, negative_prompt: str, seed: int, num_steps: int,
cfg_strength: float, duration: float):
rng = torch.Generator(device=device)
if seed >= 0:
rng.manual_seed(seed)
else:
rng.seed()
fm = FlowMatching(min_sigma=0, inference_mode='euler', num_steps=num_steps)
video_info = load_video(video, duration)
clip_frames = video_info.clip_frames
sync_frames = video_info.sync_frames
duration = video_info.duration_sec
clip_frames = clip_frames.unsqueeze(0)
sync_frames = sync_frames.unsqueeze(0)
seq_cfg.duration = duration
net.update_seq_lengths(seq_cfg.latent_seq_len, seq_cfg.clip_seq_len, seq_cfg.sync_seq_len)
audios = generate(clip_frames,
sync_frames, [prompt],
negative_text=[negative_prompt],
feature_utils=feature_utils,
net=net,
fm=fm,
rng=rng,
cfg_strength=cfg_strength)
audio = audios.float().cpu()[0]
current_time_string = datetime.now().strftime('%Y%m%d_%H%M%S')
output_dir.mkdir(exist_ok=True, parents=True)
video_save_path = output_dir / f'{current_time_string}.mp4'
make_video(video_info, video_save_path, audio, sampling_rate=seq_cfg.sampling_rate)
gc.collect()
return video_save_path
@torch.inference_mode()
def image_to_audio(image: str, prompt: str, negative_prompt: str, seed: int, num_steps: int,
cfg_strength: float, duration: float):
rng = torch.Generator(device=device)
if seed >= 0:
rng.manual_seed(seed)
else:
rng.seed()
fm = FlowMatching(min_sigma=0, inference_mode='euler', num_steps=num_steps)
image_info = load_image(image)
clip_frames = image_info.clip_frames
sync_frames = image_info.sync_frames
clip_frames = clip_frames.unsqueeze(0)
sync_frames = sync_frames.unsqueeze(0)
seq_cfg.duration = duration
net.update_seq_lengths(seq_cfg.latent_seq_len, seq_cfg.clip_seq_len, seq_cfg.sync_seq_len)
audios = generate(clip_frames,
sync_frames, [prompt],
negative_text=[negative_prompt],
feature_utils=feature_utils,
net=net,
fm=fm,
rng=rng,
cfg_strength=cfg_strength,
image_input=True)
audio = audios.float().cpu()[0]
current_time_string = datetime.now().strftime('%Y%m%d_%H%M%S')
output_dir.mkdir(exist_ok=True, parents=True)
video_save_path = output_dir / f'{current_time_string}.mp4'
video_info = VideoInfo.from_image_info(image_info, duration, fps=Fraction(1))
make_video(video_info, video_save_path, audio, sampling_rate=seq_cfg.sampling_rate)
gc.collect()
return video_save_path
@torch.inference_mode()
def text_to_audio(prompt: str, negative_prompt: str, seed: int, num_steps: int, cfg_strength: float,
duration: float):
rng = torch.Generator(device=device)
if seed >= 0:
rng.manual_seed(seed)
else:
rng.seed()
fm = FlowMatching(min_sigma=0, inference_mode='euler', num_steps=num_steps)
clip_frames = sync_frames = None
seq_cfg.duration = duration
net.update_seq_lengths(seq_cfg.latent_seq_len, seq_cfg.clip_seq_len, seq_cfg.sync_seq_len)
audios = generate(clip_frames,
sync_frames, [prompt],
negative_text=[negative_prompt],
feature_utils=feature_utils,
net=net,
fm=fm,
rng=rng,
cfg_strength=cfg_strength)
audio = audios.float().cpu()[0]
current_time_string = datetime.now().strftime('%Y%m%d_%H%M%S')
output_dir.mkdir(exist_ok=True, parents=True)
audio_save_path = output_dir / f'{current_time_string}.flac'
torchaudio.save(audio_save_path, audio, seq_cfg.sampling_rate)
gc.collect()
return audio_save_path
if __name__ == "__main__":
print("HelloWorld!")
path = text_to_audio(prompt= "So Happy Look! It's a parade!!", negative_prompt= "sad feeling, unhappy", seed = 19721121, num_steps= 30, cfg_strength=4.5, duration=3.0)
print(path)다음과 같이 함수를 분리했고
실행한 결과다.

훌륭하다.
import sys
import os
from pathlib import Path
import torch
current_path = Path(__file__).resolve()
# 부모 디렉터리를 얻어 sys.path에 추가
sys.path.append(str(current_path.parent))
parent_dir = os.path.dirname(current_path)
# 'ACE-Step' 디렉터리의 절대 경로를 구성
ace_step_path = os.path.join(parent_dir, 'ACE_STEP')
MMAudio_path = os.path.join(parent_dir, 'MMAudio')
mmaudio_path = os.path.join(MMAudio_path, 'mmaudio')
sys.path.append(mmaudio_path)
sys.path.append(MMAudio_path)
sys.path.append(ace_step_path)
# 경로 추가 확인
print(sys.path)
print(os.path.dirname(os.path.abspath(__file__)))
from TRELLIS.create import create_3d_from_image
from ACE_STEP import infer_function as ace
from MMAudio import mmaudio
from MMAudio import test_mmaudio
print("import ok")
def stable_diffusion_test():
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# 모델 로드 (이전과 동일)
pipe = StableDiffusionPipeline.from_single_file(r"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors", torch_dtype=torch.float16)
# LoRA 로드 (이전 checkpoint-500 디렉토리 지정 – 파일 대신 폴더로 변경, 에러 해결)
pipe.load_lora_weights(r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto\checkpoint-500", lora_scale=0.8) # 디렉토리 경로만! 안쪽 safetensors 자동 로드
if torch.cuda.is_available():
pipe = pipe.to('cuda')
else:
print("cuda 없음: cpu로 실행")
# 메모리 최적화 (이전처럼)
pipe.enable_attention_slicing()
# 프롬프트 (이전 그대로)
prompt = "Naruto in Nine-Tails mode with red eyes, fox-like aura, orange cloak, standing on mars crater with alien stars, fierce expression, chakra energy beams, best quality, masterpiece, detailed fur texture, epic composition, 4K resolution, dramatic shadows"
negative_prompt = "pixelated, overexposed, underexposed, noise, artifacts, fused fingers, three legs, bad proportions, extra eyes, realistic, photo, ugly face, low quality, missing details"
# 이미지 생성 (이전 그대로)
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
# 저장 (이전 그대로)
output_dir = "generated_images_naruto_tweak"
os.makedirs(output_dir, exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, f"image_{i}.png"))
print(f"{len(imgs)}개 이미지 생성 완료: {output_dir} 폴더 확인 – LoRA scale 0.8로 Naruto 특징 강조 테스트!")
# 프로 루프: checkpoint 디렉토리 지정 (파일 대신 폴더로 변경, 에러 해결 + skip 로직 추가로 끈질기게 안정)
checkpoints = [500, 1000, 1500] # 이전 루프
scales = [0.6, 0.8, 1.0] # 이전
base_path = r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto"
for ckpt in checkpoints:
ckpt_dir = os.path.join(base_path, f"checkpoint-{ckpt}")
if not os.path.exists(ckpt_dir): # 존재 안 하면 skip – 끈질기게 에러 방지
print(f"Checkpoint {ckpt} 디렉토리 없음 – 훈련 계속 돌려주세요!")
continue
for scale in scales:
pipe.load_lora_weights(ckpt_dir, lora_scale=scale) # 디렉토리 경로만! 자동 safetensors 로드
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
sub_dir = f"ckpt{ckpt}_scale{scale}"
os.makedirs(os.path.join(output_dir, sub_dir), exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, sub_dir, f"image_{i}.png"))
print("checkpoint & scale 비교 완료 – Naruto 특징 강해지는 버전 골라보세요!")
def test_minicpm():
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
# model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
# attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='flash_attention_2', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path="output.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)
def test_MMAudio():
pass
if __name__ == "__main__":
test_mmaudio.test()
test_minicpm()
audio = ace.run_ace_step_inference()
file3d = create_3d_from_image(file_path="data/doggum.jpg", output_file= "cutecat.mp4")
stable_diffusion_test()
이제 모든 코드를 실행해서 테스트 해보려고 한다. 현재 비디오 생성을 위한 함수가 준비중이다.
#필요시 minicpm 추가 종속성!(반드시 해야하는게 아님!)
pip install bitsandbytes
pip install -U transformers soxr
pip install -U timm
pip install 'accelerate>=0.26.0'AGSI서버를 위한 종속성
pip install fastapi
pip install "uvicorn[standard]"#minicpm_server.py
import torch
import uvicorn
from fastapi import FastAPI, UploadFile, File, HTTPException
from PIL import Image
from transformers import AutoModel, AutoProcessor
from decord import VideoReader, cpu
import asyncio
import os
import shutil
# 모델 로드 및 추론 함수
async def run_inference(video_path: str):
"""
모델 로드부터 추론, 자원 해제까지 모든 과정을 비동기로 처리하는 함수
"""
try:
# 모델 및 프로세서 로드
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-4',
trust_remote_code=True,
attn_implementation='flash_attention_2',
torch_dtype=torch.bfloat16
)
model = model.eval().cuda()
processor = AutoProcessor.from_pretrained(
'openbmb/MiniCPM-V-4',
trust_remote_code=True,
use_fast=True
)
tokenizer = processor.tokenizer
# 비디오 인코딩 및 추론
def encode_and_chat():
MAX_NUM_FRAMES = 64
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1)
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2
return model.chat(msgs=msgs, tokenizer=tokenizer, **params)
answer = await asyncio.to_thread(encode_and_chat)
return answer
except Exception as e:
raise e
finally:
# GPU 메모리 및 기타 자원 해제
del model
del processor
if torch.cuda.is_available():
torch.cuda.empty_cache()
app = FastAPI()
@app.post("/predict_video/")
async def predict_video(video_file: UploadFile = File(...)):
"""
비디오 파일을 받아 추론을 수행하는 RESTful API 엔드포인트
"""
temp_dir = "./temp_uploads"
os.makedirs(temp_dir, exist_ok=True)
temp_video_path = os.path.join(temp_dir, video_file.filename)
try:
# 수정된 부분: 동기식 파일 쓰기
with open(temp_video_path, "wb") as buffer:
# 동기 함수인 write를 별도의 스레드에서 실행
await asyncio.to_thread(buffer.write, await video_file.read())
# 비동기 함수 호출로 추론 시작
answer = await run_inference(temp_video_path)
return {"result": answer}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Prediction failed: {e}")
finally:
# 임시 파일 및 디렉토리 정리
if os.path.exists(temp_video_path):
os.remove(temp_video_path)
if not os.listdir(temp_dir):
os.rmdir(temp_dir)
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000)python -m uvicorn minicpm_server:app --reload
테스트 코드
import requests
import os
# 테스트할 서버 URL 및 엔드포인트
URL = "http://127.0.0.1:8000/predict_video/"
# 테스트용 비디오 파일 경로 (실제 파일 경로로 변경 필요)
# 예를 들어, 'output.mp4'라는 이름의 비디오 파일이 현재 디렉토리에 있다고 가정
VIDEO_FILE_PATH = "output.mp4"
def test_api_with_video():
"""
FastAPI 서버에 비디오 파일을 업로드하고 응답을 받는 테스트 함수
"""
if not os.path.exists(VIDEO_FILE_PATH):
print(f"Error: {VIDEO_FILE_PATH} not found.")
return
try:
# 파일을 바이너리 모드로 열기
with open(VIDEO_FILE_PATH, 'rb') as f:
# files 딕셔너리에 '비디오_파일_이름': (파일_이름, 파일_객체, MIME_타입) 형식으로 전달
files = {'video_file': (os.path.basename(VIDEO_FILE_PATH), f, 'video/mp4')}
print("Sending request to server...")
response = requests.post(URL, files=files)
# 응답 상태 코드 확인
if response.status_code == 200:
print("Request successful!")
print("Response:")
print(response.json())
else:
print(f"Request failed with status code: {response.status_code}")
print("Response:")
print(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
test_api_with_video()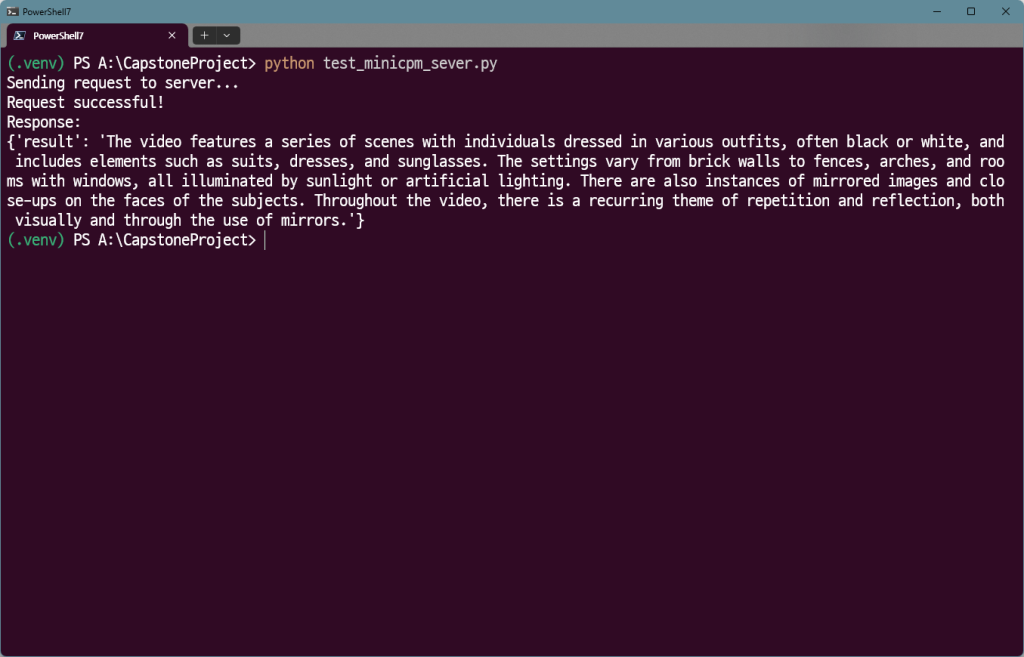
import torch
import uvicorn
import gc
from fastapi import FastAPI, UploadFile, File, HTTPException, Form
from PIL import Image
from transformers import AutoModel, AutoProcessor
from decord import VideoReader, cpu
import asyncio
import os
import shutil
import logging
from argparse import ArgumentParser
from datetime import datetime
from fractions import Fraction
from pathlib import Path
import torchaudio
import sys
current_path = Path(__file__).resolve()
# 부모 디렉터리를 얻어 sys.path에 추가
sys.path.append(str(current_path.parent))
parent_dir = os.path.dirname(current_path)
ace_step_path = os.path.join(parent_dir, 'ACE_STEP')
MMAudio_path = os.path.join(parent_dir, 'MMAudio')
mmaudio_path = os.path.join(MMAudio_path, 'mmaudio')
ace_step_path = os.path.join(parent_dir, 'ACE_STEP')
MMAudio_path = os.path.join(parent_dir, 'MMAudio')
mmaudio_path = os.path.join(MMAudio_path, 'mmaudio')
sys.path.append(mmaudio_path)
sys.path.append(MMAudio_path)
sys.path.append(ace_step_path)
from mmaudio.eval_utils import (ModelConfig, VideoInfo, all_model_cfg, generate, load_image,
load_video, make_video, setup_eval_logging)
from mmaudio.model.flow_matching import FlowMatching
from mmaudio.model.networks import MMAudio, get_my_mmaudio
from mmaudio.model.sequence_config import SequenceConfig
from mmaudio.model.utils.features_utils import FeaturesUtils
# =========================================================
# Shared Resources for MiniCPM and MMAudio
# =========================================================
log = logging.getLogger()
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
elif torch.backends.mps.is_available():
device = 'mps'
else:
log.warning('CUDA/MPS are not available, running on CPU')
dtype = torch.bfloat16
app = FastAPI()
# =========================================================
# Minicpm Model & Inference Code
# =========================================================
# 이 부분은 변경 없음: 요청 시 로드 및 해제 로직
MAX_NUM_FRAMES = 64
async def run_minicpm_inference(video_path: str):
try:
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-4',
trust_remote_code=True,
attn_implementation='flash_attention_2',
torch_dtype=torch.bfloat16
)
model = model.eval().cuda()
processor = AutoProcessor.from_pretrained(
'openbmb/MiniCPM-V-4',
trust_remote_code=True,
use_fast=True
)
tokenizer = processor.tokenizer
def encode_and_chat():
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1)
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
question = "Describe the video"
msgs = [{'role': 'user', 'content': frames + [question]}]
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2
return model.chat(msgs=msgs, tokenizer=tokenizer, **params)
answer = await asyncio.to_thread(encode_and_chat)
return answer
except Exception as e:
raise e
finally:
del model
del processor
if torch.cuda.is_available():
torch.cuda.empty_cache()
@app.post("/minicpm/predict_video/")
async def minicpm_predict_video(video_file: UploadFile = File(...)):
temp_dir = "./temp_uploads"
os.makedirs(temp_dir, exist_ok=True)
temp_video_path = os.path.join(temp_dir, video_file.filename)
try:
with open(temp_video_path, "wb") as buffer:
await asyncio.to_thread(buffer.write, await video_file.read())
answer = await run_minicpm_inference(temp_video_path)
return {"result": answer}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Prediction failed: {e}")
finally:
if os.path.exists(temp_video_path):
os.remove(temp_video_path)
if not os.listdir(temp_dir):
os.rmdir(temp_dir)
# =========================================================
# MMAudio Model & Inference Code
# =========================================================
# MMAudio 모델은 요청마다 로드하면 오버헤드가 크므로, 서버 시작 시 한 번만 로드
# (VRAM이 충분하다는 가정 하에 통합)
mmaudio_model_cfg = all_model_cfg['large_44k_v2']
mmaudio_model_cfg.download_if_needed()
output_dir = Path('./output/')
setup_eval_logging()
def get_mmaudio_model() -> tuple[MMAudio, FeaturesUtils, SequenceConfig]:
seq_cfg = mmaudio_model_cfg.seq_cfg
net: MMAudio = get_my_mmaudio(mmaudio_model_cfg.model_name).to(device, dtype).eval()
net.load_weights(torch.load(mmaudio_model_cfg.model_path, map_location=device, weights_only=True))
feature_utils = FeaturesUtils(tod_vae_ckpt=mmaudio_model_cfg.vae_path,
synchformer_ckpt=mmaudio_model_cfg.synchformer_ckpt,
enable_conditions=True,
mode=mmaudio_model_cfg.mode,
bigvgan_vocoder_ckpt=mmaudio_model_cfg.bigvgan_16k_path,
need_vae_encoder=False)
feature_utils = feature_utils.to(device, dtype).eval()
return net, feature_utils, seq_cfg
net, feature_utils, seq_cfg = get_mmaudio_model()
# MMAudio 엔드포인트: text-to-audio
@app.post("/mmaudio/text-to-audio/")
async def mmaudio_text_to_audio(prompt: str = Form(...),
negative_prompt: str = Form(""),
seed: int = Form(-1),
num_steps: int = Form(30),
cfg_strength: float = Form(4.5),
duration: float = Form(3.0)):
try:
def run_mmaudio_text_inference():
with torch.no_grad(): # CHANGE THIS LINE
rng = torch.Generator(device=device)
if seed >= 0:
rng.manual_seed(seed)
else:
rng.seed()
fm = FlowMatching(min_sigma=0, inference_mode='euler', num_steps=num_steps)
clip_frames = sync_frames = None
seq_cfg.duration = duration
net.update_seq_lengths(seq_cfg.latent_seq_len, seq_cfg.clip_seq_len, seq_cfg.sync_seq_len)
audios = generate(clip_frames,
sync_frames, [prompt],
negative_text=[negative_prompt],
feature_utils=feature_utils,
net=net,
fm=fm,
rng=rng,
cfg_strength=cfg_strength)
audio = audios.float().cpu()[0]
current_time_string = datetime.now().strftime('%Y%m%d_%H%M%S')
output_dir.mkdir(exist_ok=True, parents=True)
audio_save_path = output_dir / f'{current_time_string}.flac'
torchaudio.save(audio_save_path, audio, seq_cfg.sampling_rate)
gc.collect()
return str(audio_save_path)
path = await asyncio.to_thread(run_mmaudio_text_inference)
return {"result_path": path}
except Exception as e:
raise HTTPException(status_code=500, detail=f"MMAudio inference failed: {e}")
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000)python -m uvicorn total_api:app --reload #test_mini.py
import requests
import os
# Minicpm 테스트용 서버 URL 및 엔드포인트
URL = "http://127.0.0.1:8000/minicpm/predict_video/"
# 테스트용 비디오 파일 경로 (실제 파일 경로로 변경 필요)
VIDEO_FILE_PATH = "output.mp4"
def test_minicpm_api():
"""
Minicpm API 서버에 비디오 파일을 업로드하고 응답을 받는 테스트 함수
"""
if not os.path.exists(VIDEO_FILE_PATH):
print(f"Error: {VIDEO_FILE_PATH} not found.")
return
try:
with open(VIDEO_FILE_PATH, 'rb') as f:
files = {'video_file': (os.path.basename(VIDEO_FILE_PATH), f, 'video/mp4')}
print(f"Sending request to {URL}...")
response = requests.post(URL, files=files)
if response.status_code == 200:
print("Minicpm API Request successful!")
print("Response:")
print(response.json())
else:
print(f"Minicpm API Request failed with status code: {response.status_code}")
print("Response:")
print(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred during Minicpm API test: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
test_minicpm_api()#test_audio.py
import requests
import os
# MMAudio 테스트용 서버 URL 및 엔드포인트
URL = "http://127.0.0.1:8000/mmaudio/text-to-audio/"
def test_mmaudio_api():
"""
MMAudio API 서버에 텍스트 프롬프트를 전송하고 오디오 생성 결과를 받는 테스트 함수
"""
# 테스트에 사용할 데이터
data = {
'prompt': "A cheerful song with a piano melody and a male singer.",
'negative_prompt': "sad feeling, guitar, no singing",
'seed': 19721121,
'num_steps': 30,
'cfg_strength': 4.5,
'duration': 3.0
}
try:
print(f"Sending request to {URL} with data: {data}")
response = requests.post(URL, data=data)
if response.status_code == 200:
print("MMAudio API Request successful!")
print("Response:")
print(response.json())
# 응답으로 받은 파일 경로를 확인하여 파일이 생성되었는지 검증할 수 있습니다.
# print(f"Audio file generated at: {response.json().get('result_path')}")
else:
print(f"MMAudio API Request failed with status code: {response.status_code}")
print("Response:")
print(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred during MMAudio API test: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
test_mmaudio_api()종속성 수정
pip install numpy==2.2.6
pip install --upgrade "numba>=0.60.0"