conda create -n sd_env -y python==3.11.3
conda activate sd_env
pip install timm>=1.0.17
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
pip install xformers==0.0.29.post3 --index-url=https://download.pytorch.org/whl/cu124
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post9/triton-3.1.0-cp311-cp311-win_amd64.whl
pip install pandas pydantic
pip install diffusers transformers accelerate safetensors
pip install "huggingface_hub[cli]"
pip install https://github.com/kingbri1/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp311-cp311-win_amd64.whl
로 설치를 완료한다.
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
import os
#모델 로드, SD1.5, fp16
#"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors"
model_id = 'juggernaut_reborn'
pipe = StableDiffusionPipeline.from_single_file(r"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors", torch_dtype = torch.float16)
if torch.cuda.is_available():
pipe = pipe.to('cuda')
else:
print("cuda 없음: cpu로 실행")
#메모리 최적화
pipe.enable_attention_slicing() #메모리 부족 시 유용
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "blurry, ugly, deformed"
#이미지 생성
imgs = pipe(
prompt,
negative_prompt = negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height = 512, width = 512, #해상도
num_images_per_prompt= 4
).images
output_dir = "generated_images"
os.makedirs(output_dir, exist_ok= True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, f"image_{i}.png"))
print(f"{len(imgs)}개 이미지 생성 완료: {output_dir} 폴더 확인")
와 같이 배치로 4개의 이미지를 만들 수 있었다.
이제 lora를 훈련하는법을 정리해보려고 한다.
#diffusers 소스 설치 (예제 위해)
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
cd examples/text_to_image
pip install -r requirements.txt
#LoRA config 위해
pip install peft>=0.17.0
accelerate config default
$env:MODEL_NAME = "Q:\path\to\your\local\stable-diffusion-v1-5" # 로컬 경로로 변경! (e.g., 캐시나 다운로드 폴더 전체 경로)
$env:DATASET_NAME = "lambdalabs/naruto-blip-captions" # 이전과 동일
$env:OUTPUT_DIR = "lora_naruto" # 이전과 동일
$env:HUB_MODEL_ID = "your-hf-username/naruto-lora" # 옵션나의 경우는
$env:MODEL_NAME = "Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn"
$env:DATASET_NAME = "lambdalabs/naruto-blip-captions"
$env:OUTPUT_DIR = "lora_naruto"
cd Q:\stable-diffusion-webui\models\Stable-diffusion
curl -l -o v1-inference.yaml https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml
cd Q:\Coding\20250817\stable_diffusion_test\diffusers\scripts
---------------------------------------------------------------------------------------------
python convert_original_stable_diffusion_to_diffusers.py `
--checkpoint_path "Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors" `
--original_config_file "Q:\stable-diffusion-webui\models\Stable-diffusion\v1-inference.yaml" `
--dump_path "Q:\converted_models\juggernaut_reborn_diffusers" `
--from_safetensors
---------------------------------------------------------------------------------------------
이제 훈련 커맨드를 실행해 훈련을 진행한다
$env:MODEL_NAME = "Q:\converted_models\juggernaut_reborn_diffusers"
accelerate config default # 기본 재설정function Run-LoRA-Training {
accelerate launch --mixed_precision="bf16" train_text_to_image_lora.py `
--pretrained_model_name_or_path=$env:MODEL_NAME `
--dataset_name=$env:DATASET_NAME `
--resolution=512 --center_crop --random_flip `
--train_batch_size=1 --gradient_accumulation_steps=4 `
--max_train_steps=15000 --learning_rate=1e-4 `
--max_grad_norm=1 --lr_scheduler="cosine" --lr_warmup_steps=0 `
--output_dir=$env:OUTPUT_DIR `
--checkpointing_steps=500 `
--rank=4
}
Run-LoRA-Training
을 train.ps1으로 저장

다음과 같이 train.ps1을 실행하면 된다.
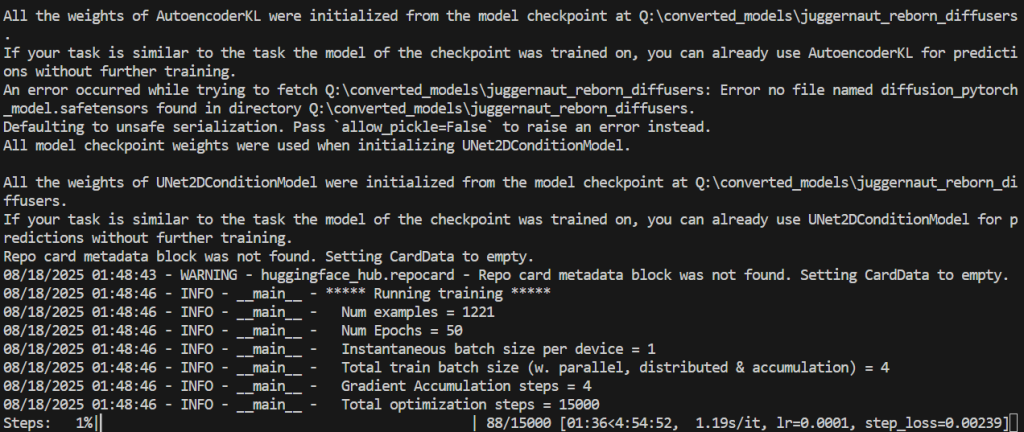
그럼 다음과 같이 학습을 시작한다.

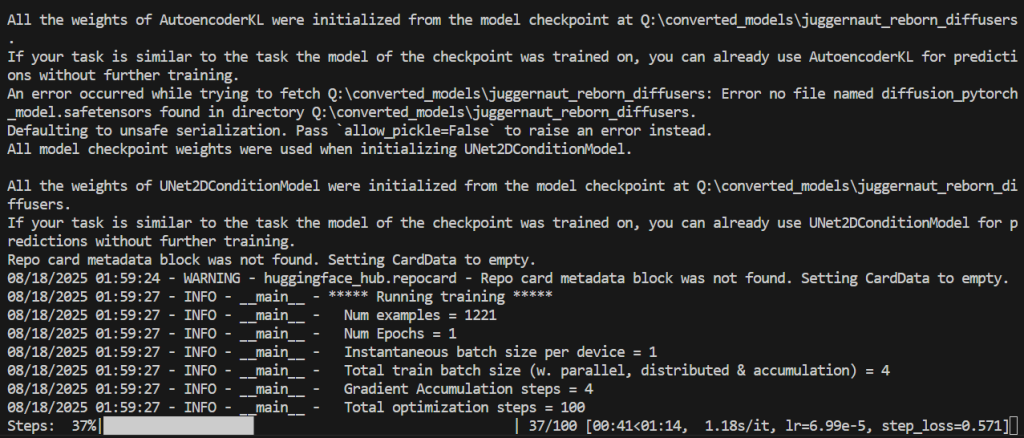
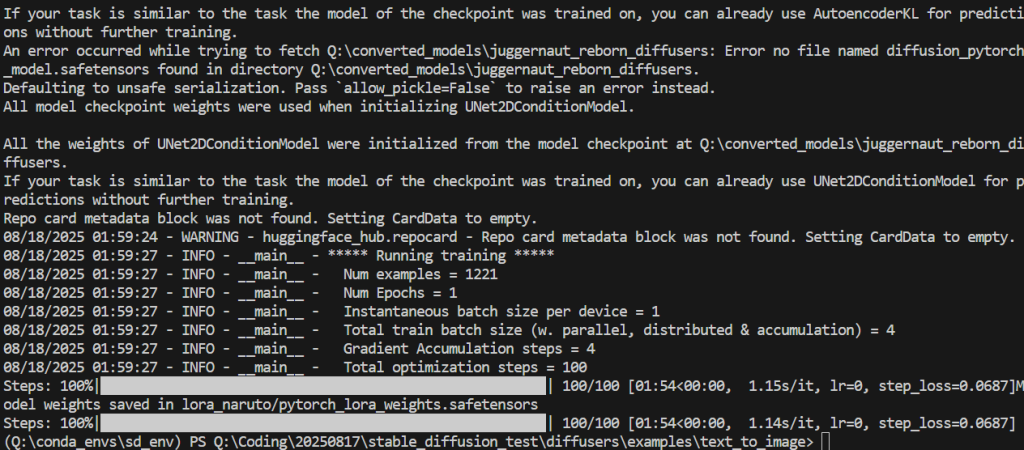
일단 15000스텝은 4~6시간 정도 걸리다고 하니 100스텝으로 줄여서 테스트
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
import os
# 모델 로드, SD1.5, fp16 (from_single_file로 .safetensors 로드, 이전 변환 필요 없음 but OK)
model_id = 'juggernaut_reborn' # 사용 안 되지만 변수 유지
pipe = StableDiffusionPipeline.from_single_file(r"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors", torch_dtype=torch.float16)
pipe.load_lora_weights(r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto\checkpoint-500\pytorch_lora_weights.safetensors")
if torch.cuda.is_available():
pipe = pipe.to('cuda')
else:
print("cuda 없음: cpu로 실행")
# 메모리 최적화
pipe.enable_attention_slicing() # 메모리 부족 시 유용
# 프롬프트 (에러 해결: positive_prompt -> prompt로 변경)
prompt = "Naruto in Nine-Tails mode with red eyes, fox-like aura, orange cloak, standing on mars crater with alien stars, fierce expression, chakra energy beams, best quality, masterpiece, detailed fur texture, epic composition, 4K resolution, dramatic shadows" # positive를 prompt로
negative_prompt = "pixelated, overexposed, underexposed, noise, artifacts, fused fingers, three legs, bad proportions, extra eyes, realistic, photo, ugly face, low quality, missing details"
# 이미지 생성 (키워드 수정: positive_prompt -> prompt)
imgs = pipe(
prompt=prompt, # 여기서 변경! 이전 오타 해법
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512, # 해상도
num_images_per_prompt=4 # 배치 4개
).images
# 저장 (이전 그대로)
output_dir = "generated_images"
os.makedirs(output_dir, exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, f"image_{i}.png"))
print(f"{len(imgs)}개 이미지 생성 완료: {output_dir} 폴더 확인")


다음과 같이 나왔다. 코드를 바꿔본다.
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
import os
# 모델 로드 (이전과 동일)
pipe = StableDiffusionPipeline.from_single_file(r"Q:\stable-diffusion-webui\models\Stable-diffusion\juggernaut_reborn.safetensors", torch_dtype=torch.float16)
# LoRA 로드 (이전 checkpoint-500 디렉토리 지정 – 파일 대신 폴더로 변경, 에러 해결)
pipe.load_lora_weights(r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto\checkpoint-500", lora_scale=0.8) # 디렉토리 경로만! 안쪽 safetensors 자동 로드
if torch.cuda.is_available():
pipe = pipe.to('cuda')
else:
print("cuda 없음: cpu로 실행")
# 메모리 최적화 (이전처럼)
pipe.enable_attention_slicing()
# 프롬프트 (이전 그대로)
prompt = "Naruto in Nine-Tails mode with red eyes, fox-like aura, orange cloak, standing on mars crater with alien stars, fierce expression, chakra energy beams, best quality, masterpiece, detailed fur texture, epic composition, 4K resolution, dramatic shadows"
negative_prompt = "pixelated, overexposed, underexposed, noise, artifacts, fused fingers, three legs, bad proportions, extra eyes, realistic, photo, ugly face, low quality, missing details"
# 이미지 생성 (이전 그대로)
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
# 저장 (이전 그대로)
output_dir = "generated_images_naruto_tweak"
os.makedirs(output_dir, exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, f"image_{i}.png"))
print(f"{len(imgs)}개 이미지 생성 완료: {output_dir} 폴더 확인 – LoRA scale 0.8로 Naruto 특징 강조 테스트!")
# 프로 루프: checkpoint 디렉토리 지정 (파일 대신 폴더로 변경, 에러 해결 + skip 로직 추가로 끈질기게 안정)
checkpoints = [500, 1000, 1500] # 이전 루프
scales = [0.6, 0.8, 1.0] # 이전
base_path = r"Q:\Coding\20250817\stable_diffusion_test\diffusers\examples\text_to_image\lora_naruto"
for ckpt in checkpoints:
ckpt_dir = os.path.join(base_path, f"checkpoint-{ckpt}")
if not os.path.exists(ckpt_dir): # 존재 안 하면 skip – 끈질기게 에러 방지
print(f"Checkpoint {ckpt} 디렉토리 없음 – 훈련 계속 돌려주세요!")
continue
for scale in scales:
pipe.load_lora_weights(ckpt_dir, lora_scale=scale) # 디렉토리 경로만! 자동 safetensors 로드
imgs = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
guidance_scale=7.5,
height=512, width=512,
num_images_per_prompt=4
).images
sub_dir = f"ckpt{ckpt}_scale{scale}"
os.makedirs(os.path.join(output_dir, sub_dir), exist_ok=True)
for i, img in enumerate(imgs):
img.save(os.path.join(output_dir, sub_dir, f"image_{i}.png"))
print("checkpoint & scale 비교 완료 – Naruto 특징 강해지는 버전 골라보세요!")



잘 나온걸로 골랐다.