의 게시글의 업그레이드 버전이라고 생각해주면 편하다. 아래의 링크를 참고했다.
https://github.com/OpenBMB/MiniCPM-o
conda activate minicpm_rebuild
pip install https://github.com/kingbri1/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp311-cp311-win_amd64.whl
일단 다음과 같이 flash-attn을 설치해주고
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path="video_test.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)코드를 다음과 같이 변경한다.

전에 사용했던 MiniCPM-V 2.6 모델을 18gb에 달하여 매우 무거웠다. 추론 자체도 매우 버거웠고…
코드를 실행하면 다음과 같이 사용할 모델을 다운 받게 된다.
생각해보면 왜 그당시의 나는 양자화된 모델을 사용하지 않았던 걸까?
일단 GPU메모리가 9gb라니까 기대감을 가지고 inference를 진행한다.
노래를 듣는 도중 다운로드가 거의 완료되었다.
결과는 매우 놀라웠다…
다음과 같은 영상을 분석하도록 시켰다.
The video features a small dog with a multicolored fur pattern, predominantly white and brown, set against a black background. Adjacent to the dog is an image of its head rendered in vibrant hues of green, blue, pink, and yellow on a gray background. Throughout the sequence, there are no significant changes or movements; the focus remains on the static images of the dog and its colorful head representation.
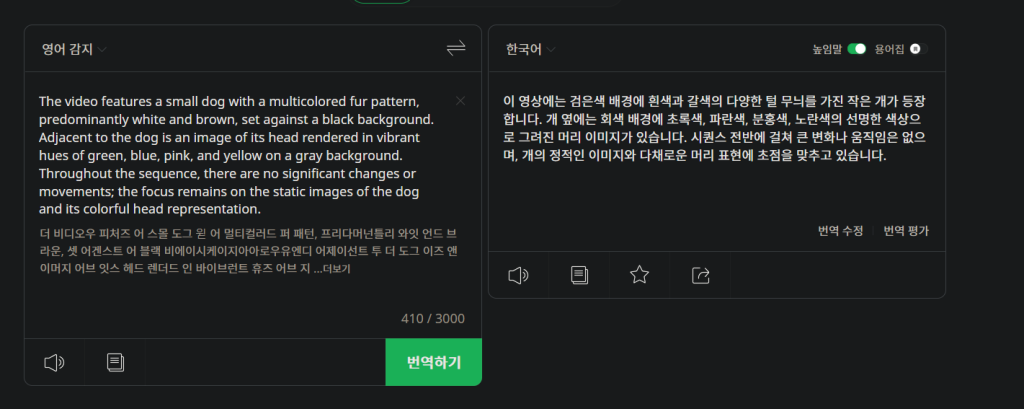
이 영상에는 검은색 배경에 흰색과 갈색의 다양한 털 무늬를 가진 작은 개가 등장합니다. 개 옆에는 회색 배경에 초록색, 파란색, 분홍색, 노란색의 선명한 색상으로 그려진 머리 이미지가 있습니다. 시퀀스 전반에 걸쳐 큰 변화나 움직임은 없으며, 개의 정적인 이미지와 다채로운 머리 표현에 초점을 맞추고 있습니다.
놀랐다. 이렇게나 빠르다니…
일단 다른 영상으로 테스트 하기 위해 해당 모델의 input을 넣기 위해서는 resizing을 해야 할 필요가 있었다.
ffmpeg -hwaccel cuda -hwaccel_output_format cuda -i "Q:\Coding\PythonCleanCode\practice_20250710\[MusRest] Rick Astley - Never Gonna Give You Up (Remastered 4K 60fps,AI) (o-YBDTqX_ZU).mp4" -vf scale_cuda=320:240 -c:v h264_nvenc -preset p4 -b:v 2M -c:a copy output.mp4와 같이 전설의 영상을 리사이즈했다. 해당 옵션은 nvidia 그래픽 카드라면 하드웨어 가속을 사용하는 옵션이다.

다음영상을 너비 320 높이 240으로 리사이즈 했다.
과연 뮤직 비디오인 만큼 vram을 먹는다.
대략 3분 정도 걸린 것 같다.
라고 하는데 번역해보자.
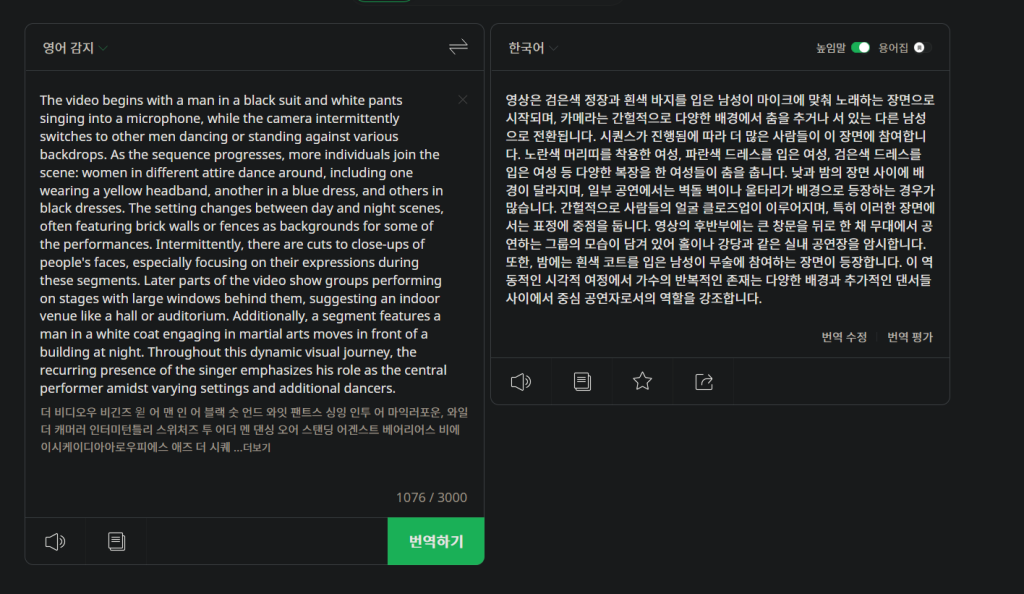
영상은 검은색 정장과 흰색 바지를 입은 남성이 마이크에 맞춰 노래하는 장면으로 시작되며, 카메라는 간헐적으로 다양한 배경에서 춤을 추거나 서 있는 다른 남성으로 전환됩니다. 시퀀스가 진행됨에 따라 더 많은 사람들이 이 장면에 참여합니다. 노란색 머리띠를 착용한 여성, 파란색 드레스를 입은 여성, 검은색 드레스를 입은 여성 등 다양한 복장을 한 여성들이 춤을 춥니다. 낮과 밤의 장면 사이에 배경이 달라지며, 일부 공연에서는 벽돌 벽이나 울타리가 배경으로 등장하는 경우가 많습니다. 간헐적으로 사람들의 얼굴 클로즈업이 이루어지며, 특히 이러한 장면에서는 표정에 중점을 둡니다. 영상의 후반부에는 큰 창문을 뒤로 한 채 무대에서 공연하는 그룹의 모습이 담겨 있어 홀이나 강당과 같은 실내 공연장을 암시합니다. 또한, 밤에는 흰색 코트를 입은 남성이 무술에 참여하는 장면이 등장합니다. 이 역동적인 시각적 여정에서 가수의 반복적인 존재는 다양한 배경과 추가적인 댄서들 사이에서 중심 공연자로서의 역할을 강조합니다.
놀랍게도 상당히 정확하다.
이제 sdpa말고 flash_attention_2를 사용해서 추론해본다.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
# model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
# attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6
attn_implementation='flash_attention_2', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-4', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
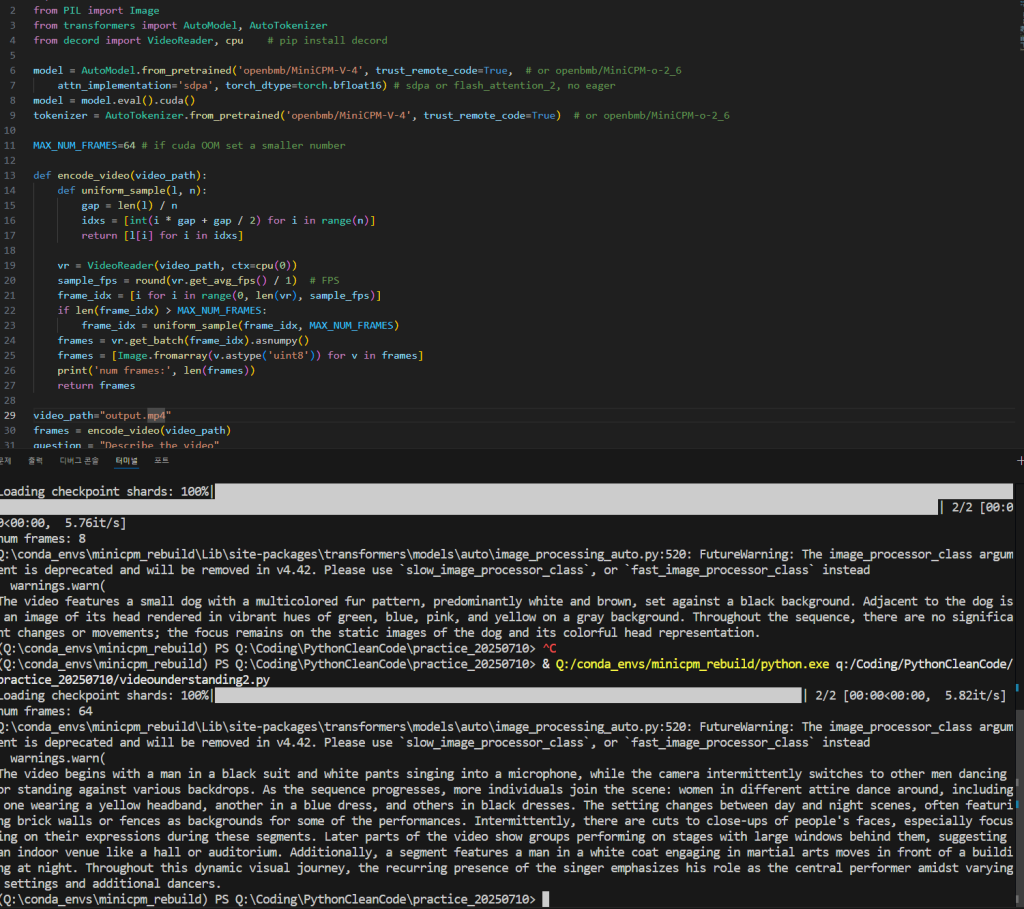
video_path="output.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params = {}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)코드를 다음과 같이 바꾸고
실행시켜 봤더니 1분도 안걸린다. 심지어 영상 녹화 프로그램 때문에 vram 용량을 살짝 초과했지만 녹화 없이 진행할 경우 12gb안에서 진행했다.
Q:\conda_envs\minicpm_rebuild\Lib\site-packages\transformers\models\auto\image_processing_auto.py:520: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
warnings.warn(
The video features a series of segments showcasing various individuals, primarily men and women, engaging in different activities against diverse backdrops. Early scenes depict close-ups of feet wearing black shoes or white pants, followed by shots of people singing into microphones, dancing, and interacting with each other. There are also moments where the focus shifts to more intimate settings like a man holding a microphone and speaking directly to the camera, as well as groups of people standing together or performing synchronized movements. Throughout the video, there is a consistent theme of performance and interaction within visually striking environments that range from simple rooms to elaborate stages adorned with arches and patterns.위와 같은 결과가 나왔는데 역시 번역해보겠다.
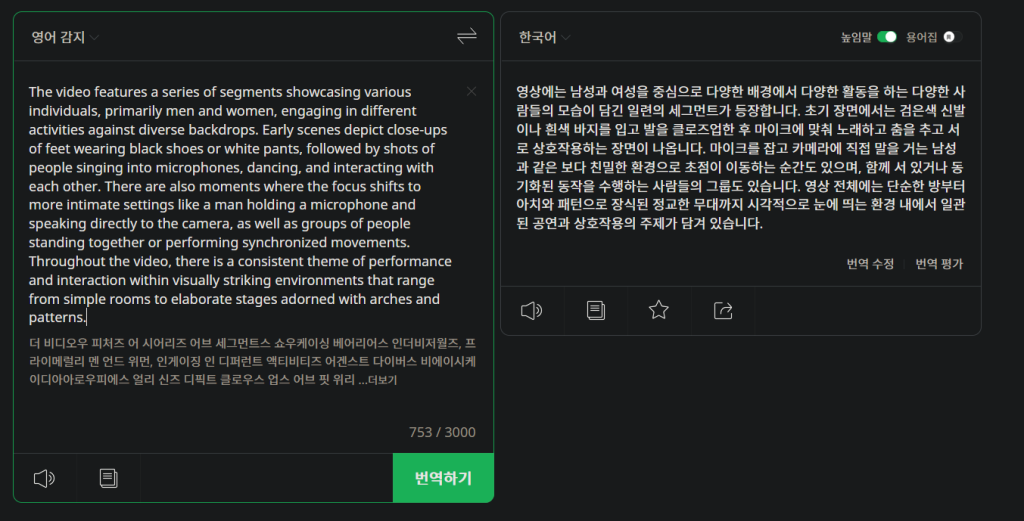
영상에는 남성과 여성을 중심으로 다양한 배경에서 다양한 활동을 하는 다양한 사람들의 모습이 담긴 일련의 세그먼트가 등장합니다. 초기 장면에서는 검은색 신발이나 흰색 바지를 입고 발을 클로즈업한 후 마이크에 맞춰 노래하고 춤을 추고 서로 상호작용하는 장면이 나옵니다. 마이크를 잡고 카메라에 직접 말을 거는 남성과 같은 보다 친밀한 환경으로 초점이 이동하는 순간도 있으며, 함께 서 있거나 동기화된 동작을 수행하는 사람들의 그룹도 있습니다. 영상 전체에는 단순한 방부터 아치와 패턴으로 장식된 정교한 무대까지 시각적으로 눈에 띄는 환경 내에서 일관된 공연과 상호작용의 주제가 담겨 있습니다.
정말인지 궁금하면 릭롤링을 당한 다음 확인하면 된다.
정말이지 AI기술의 발전의 빠름이 가속화 됨을 체감하는 요즘이다.
오늘의 결론
- minicpm4 버전은 혁신이다.
- flash-attention은 신이다.
- 여러분은 릭롤링을 당했다.