오늘은 LangCHain의 PandasDataFrameOutputParser에 대해 알아보겠습니다.
import pprint
from typing import Any, Dict
import pandas as pd
from langchain.output_parsers import PandasDataFrameOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAImodel = ChatOpenAI(temperature=0, model_name=”gpt-3.5-turbo”)
라는 코드로 부터 시작합니다. 타이타닉 CSV을 pandas를 통해 불러들이고 이를 LLM에게 전달하여 테이블에 대해 쿼리 할 수 있게 하는 예제입니다.
코드를 보시면 우선적으로 typing이라는 모듈이 보이실 것입니다.
저도 궁금해서 찾아봤는데 typing이란 모듈은 파이썬의 타입을 지정하여 인터프리터가 개발자가 의도했던 정확한 타입으로 인식할 수 있도록 도와주는 모듈인거 같더라고요 따라서 저 모듈을 사용해서 타입 힌트(type hint)를 주는 겁니다.
따라서 Any는 아무 타입이나 될 수 있어서 심지어 클래스나 , 함수도 타입으로 집어넣을 수 있습니다. Dict는 딕셔너리이고요.
from typing import Dict, Any
# Dict[str, Any]로 딕셔너리 정의
my_dict: Dict[str, Any] = {
"name": "Alice",
"age": 30,
"add_ten": lambda x: x + 10, # 람다 함수
"greet": lambda name: f"Hello, {name}!" # 또 다른 람다 함수
}
# 람다 함수 호출
print(my_dict["add_ten"](5)) # 출력: 15
print(my_dict["greet"]("Bob")) # 출력: Hello, Bob!다음과 같이 my_dict라는 딕셔너리인데요 해당 딕셔너리 가능한 타입은 Dict[str, Any]로 정의했으니 Key값으로는 str, 즉, 스트링이 들어갈 수 있고 키 값만 string이라면 어떤 타입이라도 받겠다는 의미로 Any를 사용한 것을 알 수 있습니다.
따라서 “name”, “age”, “add_ten”, “greet”과 같이 키는 string으로 지정이 되어 있고, 값은 여러 타입이 들어찬 것을 보실 수 있는데
“Alice”, 30, lambda식을 사용하여 lambda x : x + 10, lambda name : f”Hello, {name}!”
와 같이 여러 타입이 들어 찰 수 있음을 아실 수 있습니다.
# 출력 목적으로만 사용됩니다.
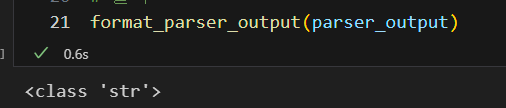
def format_parser_output(parser_output: Dict[str, Any]) -> None:
# 파서 출력의 키들을 순회합니다.
for key in parser_output.keys():
# 각 키의 값을 딕셔너리로 변환합니다.
parser_output[key] = parser_output[key].to_dict()
# 예쁘게 출력합니다.
return pprint.PrettyPrinter(width=4, compact=True).pprint(parser_output)format_parser_output함수는 파서 출력을 사전 형식으로 변환하고 출력 형식을 지정하는 데 사용됩니다.
함수의 내부를 보시면 인수로 들어가는 parser_output의 타입을 정의해 놓은 것을 보실 수 있습니다.
Dict[str, Any]라고 지정이 되어 있음을 보실 수 있는데요 아까처럼 key가 string이고 Value로 여러 자료형이 할당 될 수 있음을 의미합니다.
for key in parser_output.keys():
print(type(key))
parser_output[key] = parser_output[key].to_dict()이 코드를 보시면 keys()메서드를 호출하여 key를 반환하는 것을 보실 수 있겠는데요 앞서서 key의 type은 str이므로 반환하는 타입도 str이 되겠습니다.

to_dict()메서드 다음과 같습니다.
DataFrame.to_dict(orient=’dict’, into=)
아래의 링크에 to_dict()메서드의 사용법에 대해서 잘 설명이 되어 있습니다.
따라서 해당 메서드를 통해 딕셔너리로 반환받은 다음 pprint로 깔끔하게 출력하는 함수입니다.
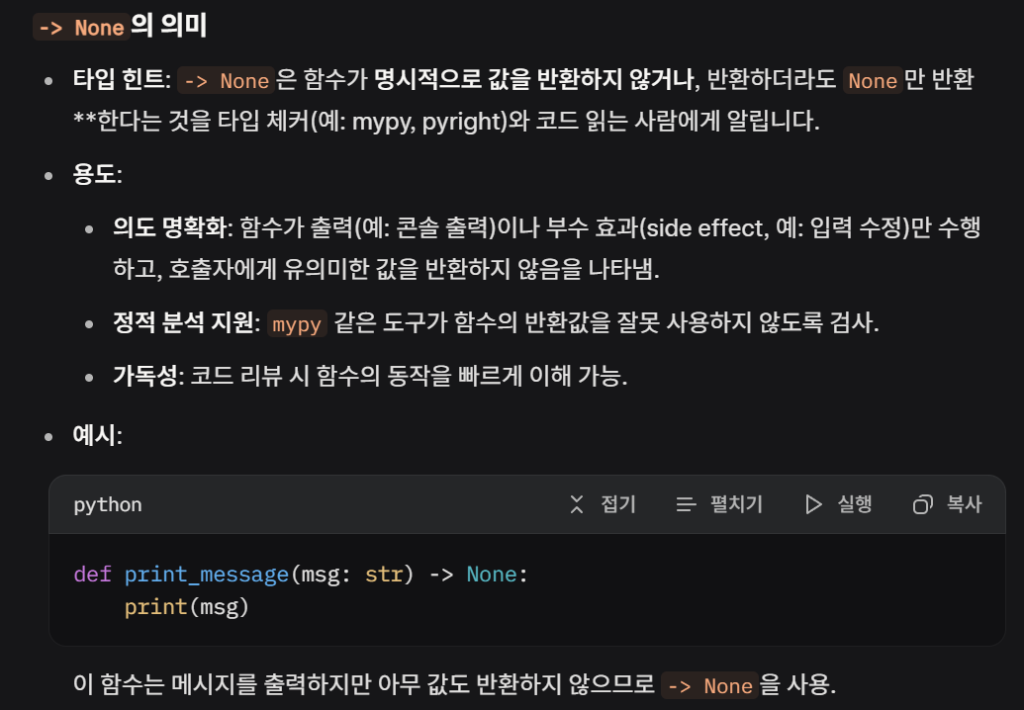
None이므로 아무것도 반환하지 않습니다.
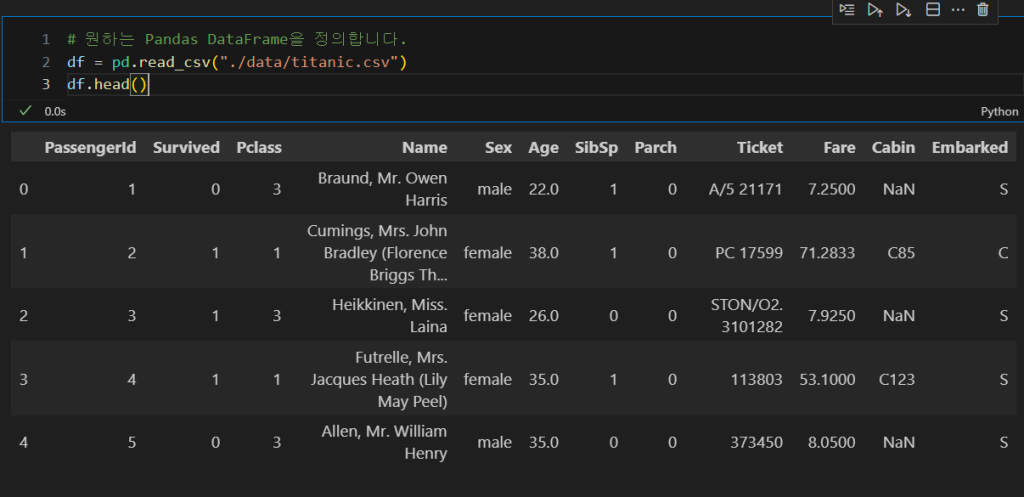
pandas 라이브러리를 활용하여 다음과 같이 테이블을 로드합니다.
하나 알아두면 좋은 점은 csv는 내부 구조가 매우 단순합니다. 줄바꿈과 콤마(,)만으로 행열을 구분합니다.
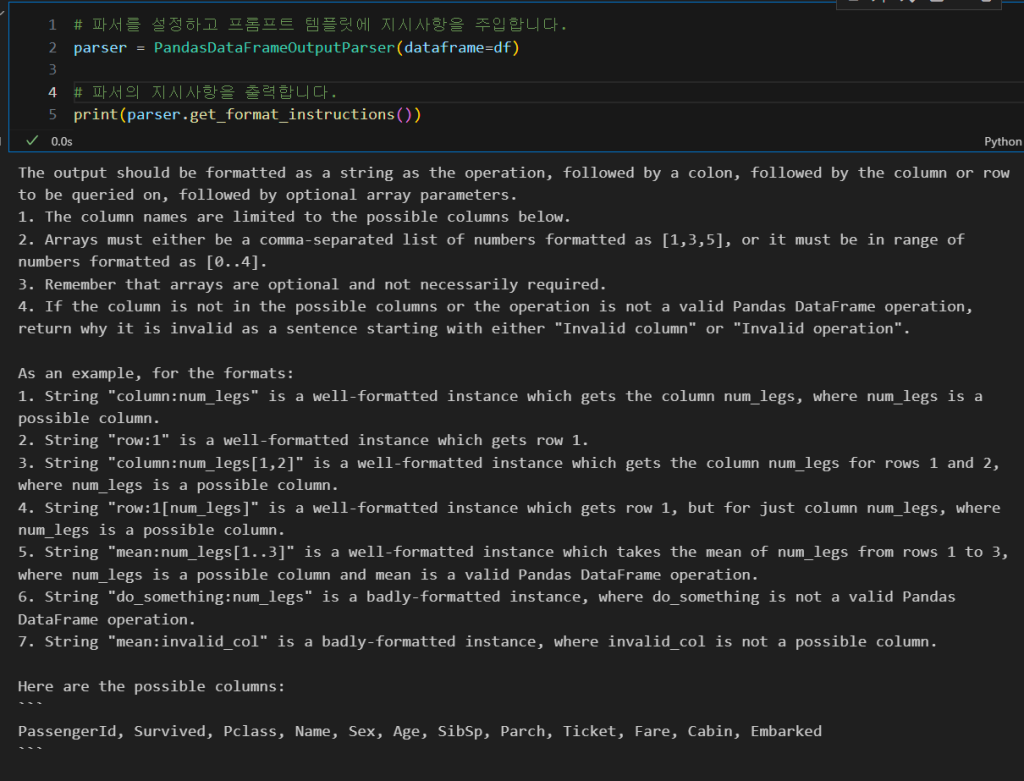
# 파서를 설정하고 프롬프트 템플릿에 지시사항을 주입합니다.
parser = PandasDataFrameOutputParser(dataframe=df)
# 파서의 지시사항을 출력합니다.
print(parser.get_format_instructions())와 같이 파서를 설정합니다.
The output should be formatted as a string as the operation, followed by a colon, followed by the column or row to be queried on, followed by optional array parameters.
1. The column names are limited to the possible columns below.
2. Arrays must either be a comma-separated list of numbers formatted as [1,3,5], or it must be in range of numbers formatted as [0..4].
3. Remember that arrays are optional and not necessarily required.
4. If the column is not in the possible columns or the operation is not a valid Pandas DataFrame operation, return why it is invalid as a sentence starting with either "Invalid column" or "Invalid operation".
As an example, for the formats:
1. String "column:num_legs" is a well-formatted instance which gets the column num_legs, where num_legs is a possible column.
2. String "row:1" is a well-formatted instance which gets row 1.
3. String "column:num_legs[1,2]" is a well-formatted instance which gets the column num_legs for rows 1 and 2, where num_legs is a possible column.
4. String "row:1[num_legs]" is a well-formatted instance which gets row 1, but for just column num_legs, where num_legs is a possible column.
5. String "mean:num_legs[1..3]" is a well-formatted instance which takes the mean of num_legs from rows 1 to 3, where num_legs is a possible column and mean is a valid Pandas DataFrame operation.
6. String "do_something:num_legs" is a badly-formatted instance, where do_something is not a valid Pandas DataFrame operation.
7. String "mean:invalid_col" is a badly-formatted instance, where invalid_col is not a possible column.
Here are the possible columns:
```
PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked
```위는 해당 코드 실행 결과로 출력된 지시사항이 되겠습니다.
# 열 작업 예시입니다.
df_query = "Age column 을 조회해 주세요."
# 프롬프트 템플릿을 설정합니다.
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{question}\n",
input_variables=["question"], # 입력 변수 설정
partial_variables={
"format_instructions": parser.get_format_instructions()
}, # 부분 변수 설정
)
# 체인 생성
chain = prompt | model | parser
# 체인 실행
parser_output = chain.invoke({"question": df_query})
# 출력
format_parser_output(parser_output)위와 같이 invoke할 수 있는 코드가 있습니다.
prompt를 정의하고 내부적으로 question이라는 키에 df_query라는 값을 채워서 질문부분을 채워 넣고 input_variables라는 인수에 [“question”]라고 설정하여 invoke시에 인자로 딕셔너리를 받을 때 그 딕셔너리에 question을 집어 넣어 프롬프트 내부 질문 부분 (question)을 채울 수 있게 하였습니다. 다시 말씀드리자면 question의 value로 채워지는 것은 df_query입니다.
그리고 partial_variables로 앞서 정의한 지침 parser을 가져오는 것입니다. ‘지침’입니다.
이와 같은 지침을 참고하여 출력을 하도록 알려준다는 의미가 됩니다.
template=”Answer the user query.\n{format_instructions}\n{question}\n”,
따라서 위의 문장은 문맥적으로 format_instructions(즉, 지침)을 따라서 question(질의문)에 응답하라는 의미가 됩니다.
그리고 chain pipeline을 정의하여 프롬프트 | 모델 | 파서의 형식으로 최종적으로 파서에 의해 정돈된 모습으로 나타납니다.
format_parser_output(parser_output)을 사용하여 이쁘게 정리했으므로
<class 'str'>
{'Age': {0: 22.0,
1: 38.0,
2: 26.0,
3: 35.0,
4: 35.0,
5: nan,
6: 54.0,
7: 2.0,
8: 27.0,
9: 14.0,
10: 4.0,
11: 58.0,
12: 20.0,
13: 39.0,
14: 14.0,
15: 55.0,
16: 2.0,
17: nan,
18: 31.0,
19: nan}}와 같은 형식으로 정돈되어 나타납니다.
그리고 편의를 위해 프롬프트를 파파고로 번역시켜봤습니다.
출력은 문자열로 형식화된 후 콜론, 쿼리할 열 또는 행, 선택적 배열 매개변수로 순서를 정해야 합니다.
1. 열 이름은 아래 가능한 열로 제한됩니다.
2. 배열은 [1,3,5]로 형식화된 쉼표로 구분된 숫자 목록이거나 [0.4]로 형식화된 숫자 범위 내에 있어야 합니다.
3. 배열은 선택 사항이며 반드시 필요한 것은 아닙니다.
4. 열이 가능한 열에 없거나 해당 연산이 유효한 Pandas DataFrame 연산이 아닌 경우, "무효 열" 또는 "무효 연산"으로 시작하는 문장으로 왜 유효하지 않은지 반환합니다.
예를 들어, 형식의 경우:
1. 문자열 "column:num_legs"는 num_legs 열을 얻을 수 있는 잘 형식화된 인스턴스입니다. 여기서 num_legs는 가능한 열입니다.
2. 문자열 "row:1"은 행 1을 얻는 잘 형식화된 인스턴스입니다.
3. 문자열 "column:num_legs[1,2]"는 행 1과 행 2에 대해 num_legs 열을 얻는 잘 형식화된 인스턴스입니다. 여기서 num_legs는 가능한 열입니다.
4. 문자열 "row:1[num_legs]"는 행 1을 얻는 잘 형식화된 인스턴스이지만, num_legs가 가능한 열인 열 num_legs에 대해서만 가능합니다.
5. 문자열 "mean:num_legs[1.3]"은 행 1에서 행 3까지의 num_legs의 평균을 취하는 잘 형식화된 인스턴스입니다. 여기서 num_legs는 가능한 열이고 mean은 유효한 Pandas DataFrame 연산입니다.
6. 문자열 "do_something:num_legs"는 잘못된 형식의 인스턴스로, 여기서 do_something은 유효한 Pandas DataFrame 작업이 아닙니다.
7. 문자열 "mean:invalid_col"은 형식이 좋지 않은 인스턴스로, invalid_col은 가능한 열이 아닙니다.
가능한 열은 다음과 같습니다:
```
PassengerId, 생존자, Pclass, 이름, 성별, 나이, SibSp, 파르크, 티켓, 요금, 객실, 탑승
```위와 같이 굉장히 구체적으로 지침을 내리는 것을 보실 수 있습니다.
# 행 조회 예시입니다.
df_query = "Retrieve the first row."
# 체인 실행
parser_output = chain.invoke({"question": df_query})
# 결과 출력
format_parser_output(parser_output)위와 같이 첫번째 행을 검색하는 코드가 있다고 생각합니다.
{'0': {'Age': 22.0,
'Cabin': nan,
'Embarked': 'S',
'Fare': 7.25,
'Name': 'Braund, '
'Mr. '
'Owen '
'Harris',
'Parch': 0,
'PassengerId': 1,
'Pclass': 3,
'Sex': 'male',
'SibSp': 1,
'Survived': 0,
'Ticket': 'A/5 '
'21171'}}와 같이 첫 번째 행을 출력합니다.
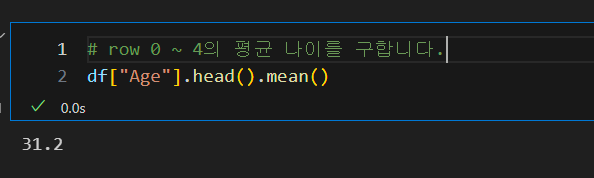
와 같이 승객들의 평균 나잇대도 구할 수 있습니다.
# 임의의 Pandas DataFrame 작업 예시, 행의 수를 제한합니다.
df_query = "Retrieve the average of the Ages from row 0 to 4."
# 체인 실행
parser_output = chain.invoke({"question": df_query})
# 결과 출력
print(parser_output)
#결과
{'mean': 31.2}다음과 같이 임의로 행의 수를 제한하여 쿼리 할 수도 있습니다.
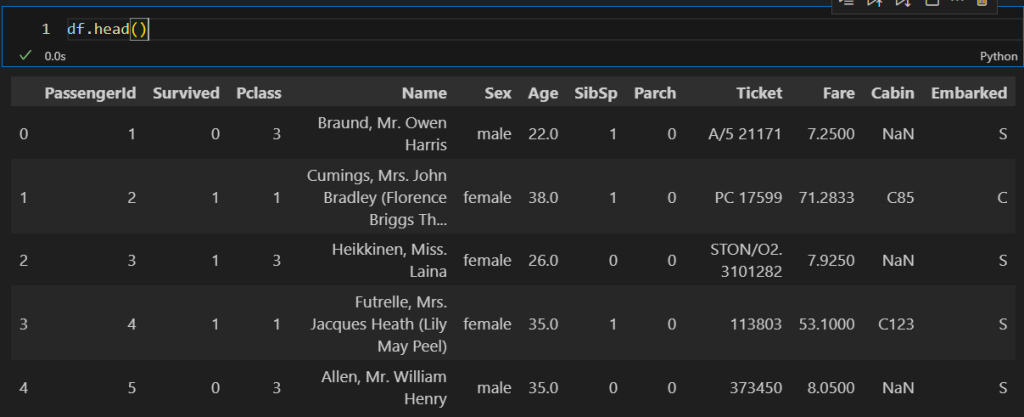
요금에 대한 평균 가격을 산정하는 예시인데요
# 잘못 형식화된 쿼리의 예시입니다.
df_query = "Calculate average `Fare` rate."
# 체인 실행
parser_output = chain.invoke({"question": df_query})
# 결과 출력
print(parser_output)# 결과 검증
df["Fare"].mean()22.19937 와 같은 결과가 나오는 것을 아실 수 있겠습니다.