※TeddyLee 강사님의 강의를 보고 제 나름 정리하고 내용을 절충해서 저 나름대로 정리한 내용입니다.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
chat_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"당신은 요약 전문 AI 어시스턴트입니다. 당신의 임무는 주요 키워드로 대화를 요약하는 것입니다.",
),
MessagesPlaceholder(variable_name="conversation"),
("human", "지금까지의 대화를 {word_count} 단어로 요약합니다."),
]
)
chat_prompt위의 코드를 설명하겠습니다. langchain_core.output_parsers import StrOutputParser 보터 보도록 하겠습니다.
위의 코드는 LangChain에서 Output이 어떤 형태로 나올지 결정하기 위해서 import한 코드입니다.
OpenAI사의 ChatGPT를 개발자의 프로젝트에 사용하기 위해 LangChain을 사용하는데 이때 OpenAI의 ChatGPT를 사용하기 위한 LangChain입니다. 그런데 LangChain은 LCEL(LangChain Expression Language)라는 랭체인만의 독특한 문법이 존재합니다.
이런한 문법과 랭체인에서는 PromptTemplate이라는 개념이 존재합니다. 이는 AI(LLM)에게 페르소나를 부여하고 어떻게 사용자와 티키타카할지를 사전에 알려주는 것이라고 볼 수 있습니다.
이 템플릿을 잘만 적용하면 개발자는 LLM에게 원하는 성격을 부여하고 원하는 형식의 답변을 받을 수 있게되는 것이라고 할 수 있습니다.
그래서 나온 결과물은 AI.Prompt형식으로 나오는데 우리가 원하는 건 대부분 깔끔한 str형식으로 나오는 것을 원할 것입니다. 따라서 StrOuputParser라는 것을 파이프라인에 추가하여 최종적으로 Chain의 출력을 str로 정리해서 받아 볼 수 있는 것입니다.
여기서 파이프라인이라는 개념이 등장하게 됩니다.
# chain 생성
chain = chat_prompt | llm | StrOutputParser()이런 코드가 파이프라인을 정의하는 코드입니다.
우선 chat_prompt라는 것을 ChatPromptTemplate.from_messages(~)를 통해 define했습니다.
아직 확정된 메시지가 아니지만 나중에 언젠가 채워질 메시지를 Placeholder로 잡아두는 것을 메시지 플레이스 홀더라고 합니다.
구체적으로는 Chatbot을 활용할 때 대화기록이 누적되게 되는데 나중에 대화를 할 때 사용해야 하므로 잠시 잡아두었다가 대화를 이어나가면서 사용하게 되는 것입니다. 이렇게 메시지를 나중에 넣어주기 위해서 위치만 잡아주는 것이라고 볼 수 있습니다. 이런 기능을 활용하기 위해 MessagePlaceholder를 사용하여 메시지를 잡아두는 역할을 할 수 있는 코드가 되겠습니다.
/formatted_chat_prompt = chat_prompt.format(
word_count=5,
conversation
(“human”, “안녕하세요! booleanjars.com에 오신 것을 환영합니다.”),
(“ai”, “반가워요! 앞으로 잘 부탁 드립니다.”),
],
)
print(formatted_chat_prompt)
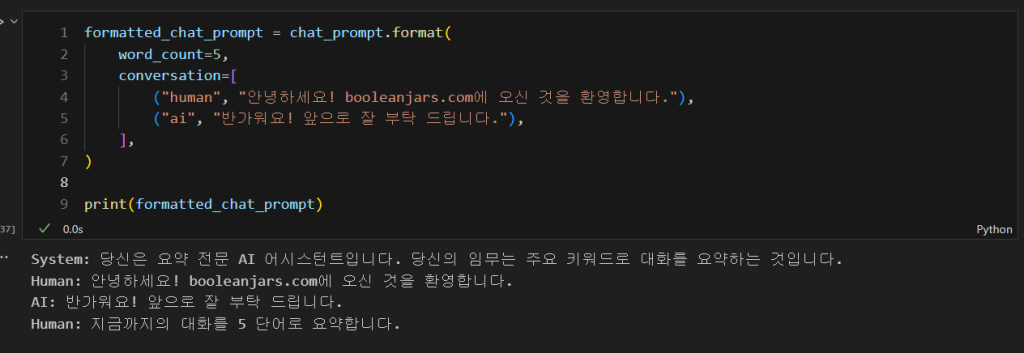
이런식으로 앞선 word_count에 5를 넣어주고 conversation을 새로 넣어줬을 경우
# chain 생성
chain = chat_prompt | llm | StrOutputParser()
와 같이 파이프라인을 define하고 # chain 실행 및 결과확인
chain.invoke(
{
"word_count": 5,
"conversation": [
(
"human",
"안녕하세요! 저는 오늘 새로 입사한 테디 입니다. 만나서 반갑습니다.",
),
("ai", "반가워요! 앞으로 잘 부탁 드립니다."),
],
}
)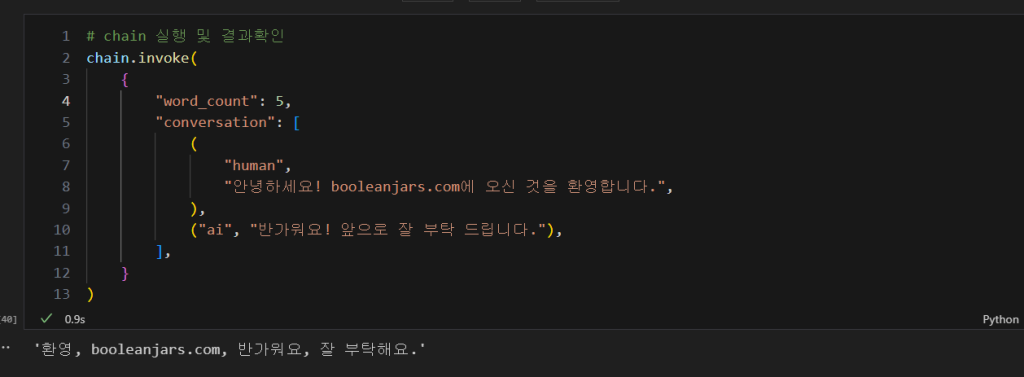
마치 AI가 제 블로그에 놀러왔고 AI에게 제가 환영인사를 건네고 AI가 답변하는 모습같군요.
메시지를 잘 보시면 다섯 단어로 잘 요약 해준 것을 보실 수 있습니다.
그럼 이제 FewShotTemplate에 대해 정리해보고자 합니다.
FewShotTemplate이란?
신입사원을 가르치는 직장 상사의 시선을 이해하시면 쉽게 이해하실 수 있습니다.
GPT에게 참고할만한 모범적인 대답을 여러개 알려주는 것을 FewShotTemplate이라고 할 수 있습니다.
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
examples = [
{
"question": "스티브 잡스와 아인슈타인 중 누가 더 오래 살았나요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 스티브 잡스는 몇 살에 사망했나요?
중간 답변: 스티브 잡스는 56세에 사망했습니다.
추가 질문: 아인슈타인은 몇 살에 사망했나요?
중간 답변: 아인슈타인은 76세에 사망했습니다.
최종 답변은: 아인슈타인
""",
},
{
"question": "네이버의 창립자는 언제 태어났나요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 네이버의 창립자는 누구인가요?
중간 답변: 네이버는 이해진에 의해 창립되었습니다.
추가 질문: 이해진은 언제 태어났나요?
중간 답변: 이해진은 1967년 6월 22일에 태어났습니다.
최종 답변은: 1967년 6월 22일
""",
},
{
"question": "율곡 이이의 어머니가 태어난 해의 통치하던 왕은 누구인가요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 율곡 이이의 어머니는 누구인가요?
중간 답변: 율곡 이이의 어머니는 신사임당입니다.
추가 질문: 신사임당은 언제 태어났나요?
중간 답변: 신사임당은 1504년에 태어났습니다.
추가 질문: 1504년에 조선을 통치한 왕은 누구인가요?
중간 답변: 1504년에 조선을 통치한 왕은 연산군입니다.
최종 답변은: 연산군
""",
},
{
"question": "올드보이와 기생충의 감독이 같은 나라 출신인가요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 올드보이의 감독은 누구인가요?
중간 답변: 올드보이의 감독은 박찬욱입니다.
추가 질문: 박찬욱은 어느 나라 출신인가요?
중간 답변: 박찬욱은 대한민국 출신입니다.
추가 질문: 기생충의 감독은 누구인가요?
중간 답변: 기생충의 감독은 봉준호입니다.
추가 질문: 봉준호는 어느 나라 출신인가요?
중간 답변: 봉준호는 대한민국 출신입니다.
최종 답변은: 예
""",
},
]위와 같은 형식으로 AI에게 어떻게 문답할지를 논리적으로 알려주는 것이라고 할 수 있겠습니다.
example_prompt = PromptTemplate.from_template(
"Question:\n{question}\nAnswer:\n{answer}"
)
print(example_prompt.format(**examples[0]))
이제 PromptTemplate.from_template으로 프롬프트 템플릿을 define해줍니다. 참고로 example_prompt안의 Question을 딕셔너리의 키값의 대응되는 value를 format으로 채워줍니다. (**examples[0])는 unpacking연산자를 표현하는 것입니다. unpacking해서 집어 넣어주는 것입니다.
리스트의 unpacking과 딕셔너리의 unpacking에 대해서 차이점을 잠시 정리해보려고 합니다.
우선 list unpacking에 대해서 설명 드리자면
def number_generator():
for i in range(1, 10 + 1):
yield i
for i in number_generator():
print(i, end = ' ')
print('\n' + str(number_generator))
n = number_generator()
sample = list()
for i in n:
sample.append(i)
print(sample)
def arg_sum(*args):
sum = 0
for elem in args:
sum += elem
return sum
res = arg_sum(*sample)

와 같이 리스트의 요소를 unpack하여주는 기능을 말합니다.
그리고 ** 연산자는 키워드 인자 언패킹이라고 해서 키-값 쌍을 함수의 키워드 인자로 분리할 때 사용합니다.
def greet(name, age):
print(f"안녕하세요, {name}님! 나이는 {age}세입니다.")
info = {'name': '홍길동', 'age': 30}
greet(**info)
# 출력: 안녕하세요, 홍길동님! 나이는 30세입니다.
따라서 **examples는 여러 str이 들어있는 list형태로 변환이 되고 그중 [0]번째 요소를 출력해서 아인슈타인이 된 것이죠.
그리고 이것은 하나만 변환한 것이므로 OneShot이 됩니다.
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Question:\n{question}\nAnswer:",
input_variables=["question"],
)
question = "Google이 창립된 연도에 Bill Gates의 나이는 몇 살인가요?"
final_prompt = prompt.format(question=question)
print(final_prompt)와 같이 쓰게 되어
answer = llm.invoke(final_prompt)
for token in answer:
print(token, end = '', flush=True)
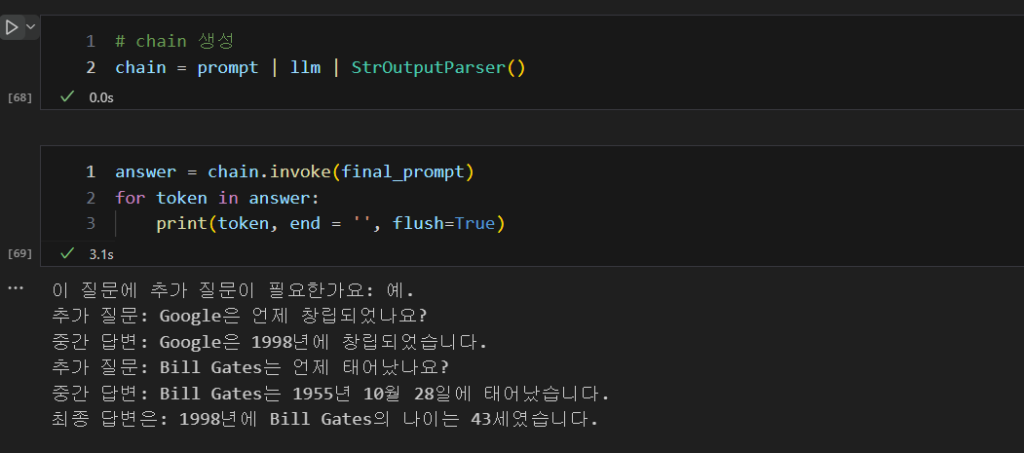
StrOutPutParser를 사용하여 깔끔하게 정리하면 다음과 같이 나오게 됩니다.
일단 내용이 길어지므로 다음 글에서 마저 하도록 하겠습니다.